
【笔记】吴恩达Generative AI with Large Language Models --- Week2
本篇为学习吴恩达DeepLearning.AI平台下《Generatvie AI with Large Language Models》笔记
课程:DeepLearning.AI — Generative AI with Large Language Models
链接:Generative AI with Large Language Models
Week2: Fine-tuning and evaluating large language models
本周的内容主要学习instruction fine-tuning(指令微调)和parameter-efficient fine-tuning, PEFT(参数高效微调)。
预训练模型虽然已经学到了很多知识,但并不一定擅长理解和执行指令,因此需要通过instruction tuning(指令调优)来调整模型行为。后续内容还要介绍微调中的catastrophic forgetting(灾难性遗忘)问题,以及像 LoRA(低秩适配)这样的高效微调方法。这些方法可以在更低的计算和存储成本下提升模型在特定任务上的表现。
Instruction Fine-Tuning
1. Instruction Fine-Tuning
Instruction fine-tuning(指令微调)是用带有prompt-completion pairs(提示-回答对)的标注数据,对预训练模型继续训练,让模型更好地理解和执行具体指令。相比只靠 zero-shot 或 few-shot prompting,instruction fine-tuning 对小模型更有效,也不会额外占用太多 context window。它本质上属于supervised learning(监督学习),通过比较模型输出和标准答案之间的差异,使用cross-entropy loss(交叉熵损失)来更新模型参数。完成训练后,模型会变成更擅长按指令完成任务的instruct model(指令模型)。
2. Fine-tuning on a single task
Single-task fine-tuning(单任务微调)是指只针对某一个具体任务对预训练模型进行微调,比如 summarization(摘要生成)或 sentiment analysis(情感分析)。这种方法通常只需要较少的数据,也能带来不错的效果,例如几百到一千条样本就可能有明显提升。
不过,它也有一个潜在问题:catastrophic forgetting(灾难性遗忘)。因为 full fine-tuning 会直接修改原模型的参数,所以模型在某一个任务上变强的同时,可能会削弱它原本在其他任务上的能力。
如果应用场景只关心单一任务,那么这个问题不一定重要;但如果希望模型继续保持多任务能力,可以考虑multi-task fine-tuning(多任务微调),或者使用PEFT(参数高效微调)来减少遗忘问题。
3. Multi-task Instruction Fine-Tuning
Multi-task fine-tuning(多任务微调)是在一个混合数据集上同时训练多个任务,例如 summarization、review rating、code translation 和 entity recognition。这样做可以在提升多个任务表现的同时,减少 single-task fine-tuning 可能带来的 catastrophic forgetting(灾难性遗忘)。不过,它通常需要更多数据,一般可能需要 50,000 到 100,000 条训练样本。
课程里提到的一个典型例子是 FLAN 系列模型。FLAN 是通过多任务指令微调得到的 instruct model,例如 FLAN-T5。这类模型在很多任务上都有不错的泛化能力。
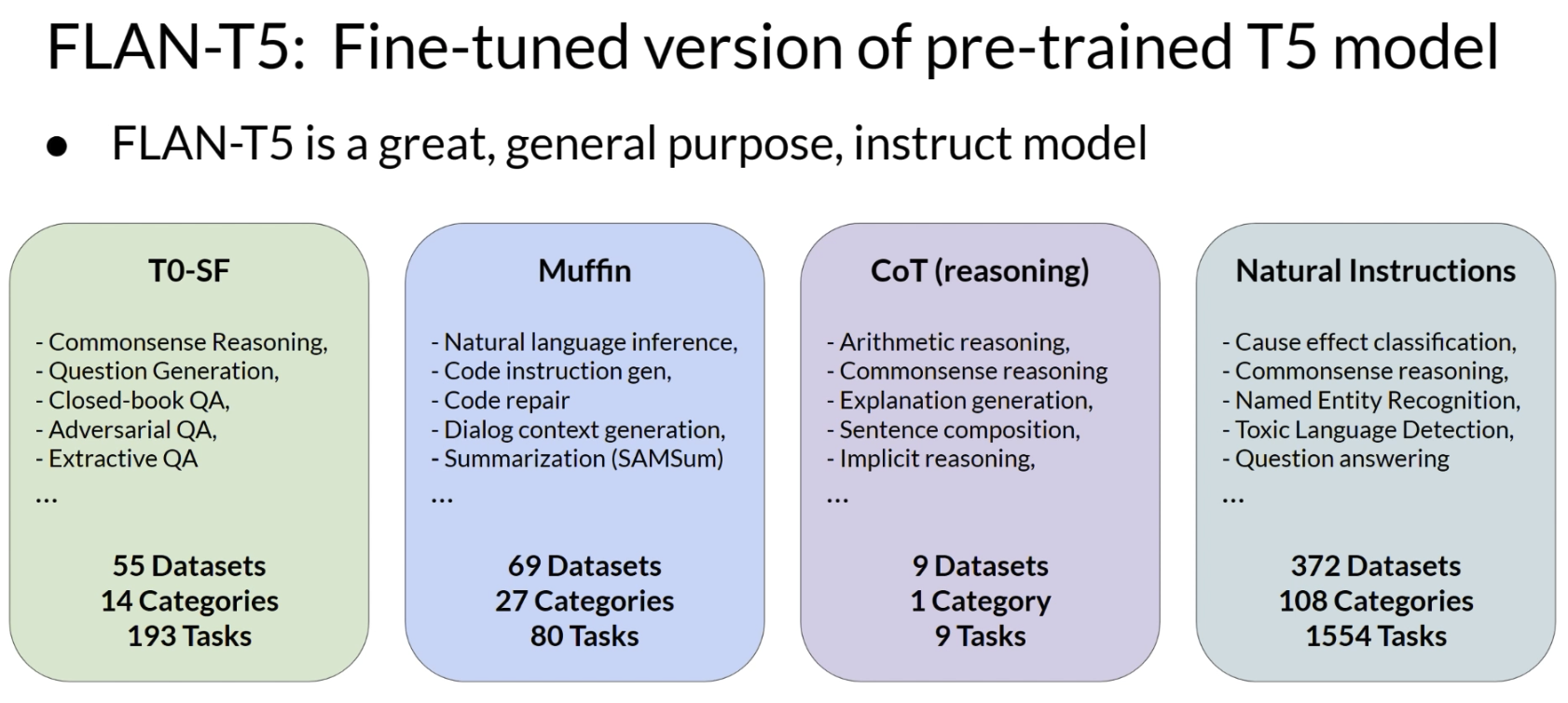
上图说明FLAN-T5不是只在单一任务上训练,而是使用多个任务集合进行多任务指令微调,因此它是一个能力较全面的general-purpose instruct model。
但即使是通用模型,在特定场景下也可能还不够好,所以还可以继续用 domain-specific data(领域数据) 做额外微调。比如课程里的例子就是在 DIALOGSUM 数据集上进一步训练 FLAN-T5,让它更擅长总结客服对话。这样可以让模型输出更准确,也减少编造信息的问题。
Model Evaluation
1. Model evaluation
Model evaluation 用来衡量 fine-tuned model 是否比 base model 表现更好。对于传统机器学习任务,可以直接使用 accuracy,但 LLM 的输出是自然语言且具有 non-deterministic 的特点,因此评估更加复杂。两个句子可能字面不同但语义接近,也可能只差一个词但含义完全相反。
在传统机器学习中,如果输出标签是确定的,常见指标是 accuracy,即正确预测数占总预测数的比例。

对于生成任务,在看的课程中主要介绍了两类常见自动评估指标:ROUGE 和 BLEU。ROUGE 主要用于 text summarization,BLEU 主要用于 machine translation。
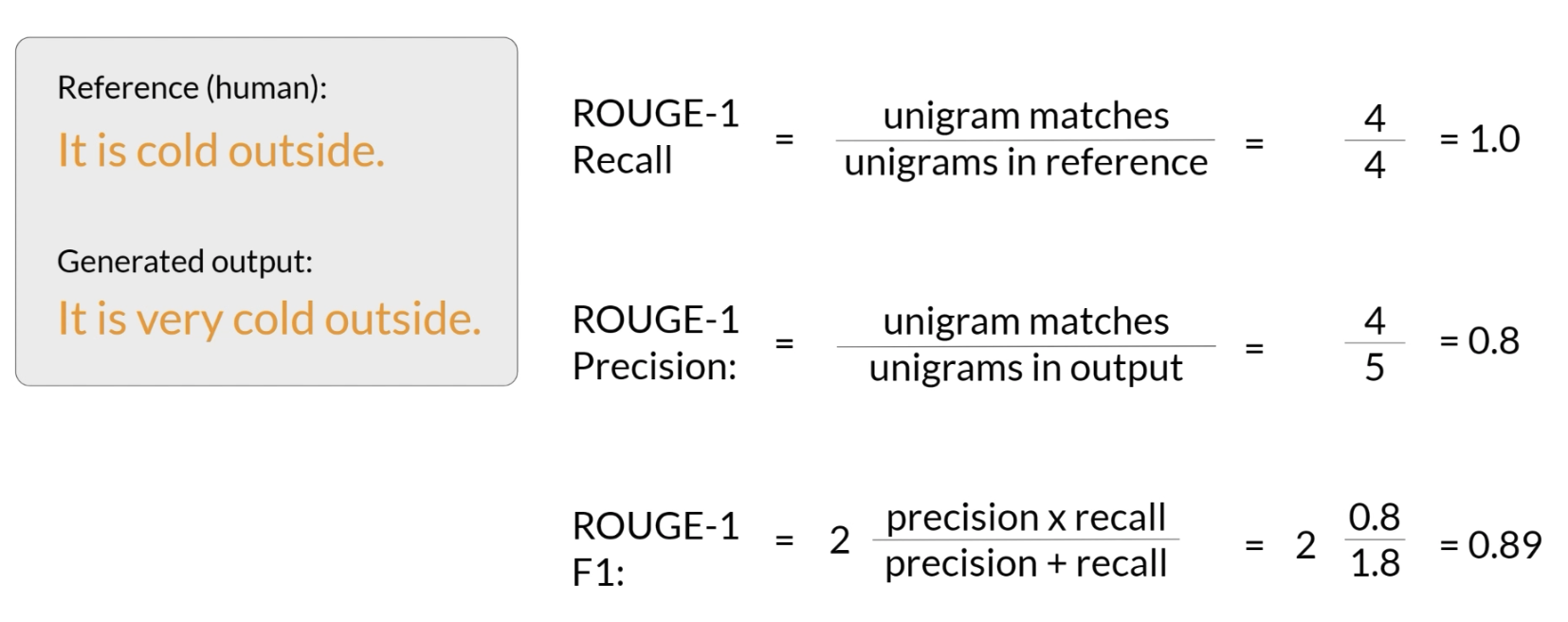
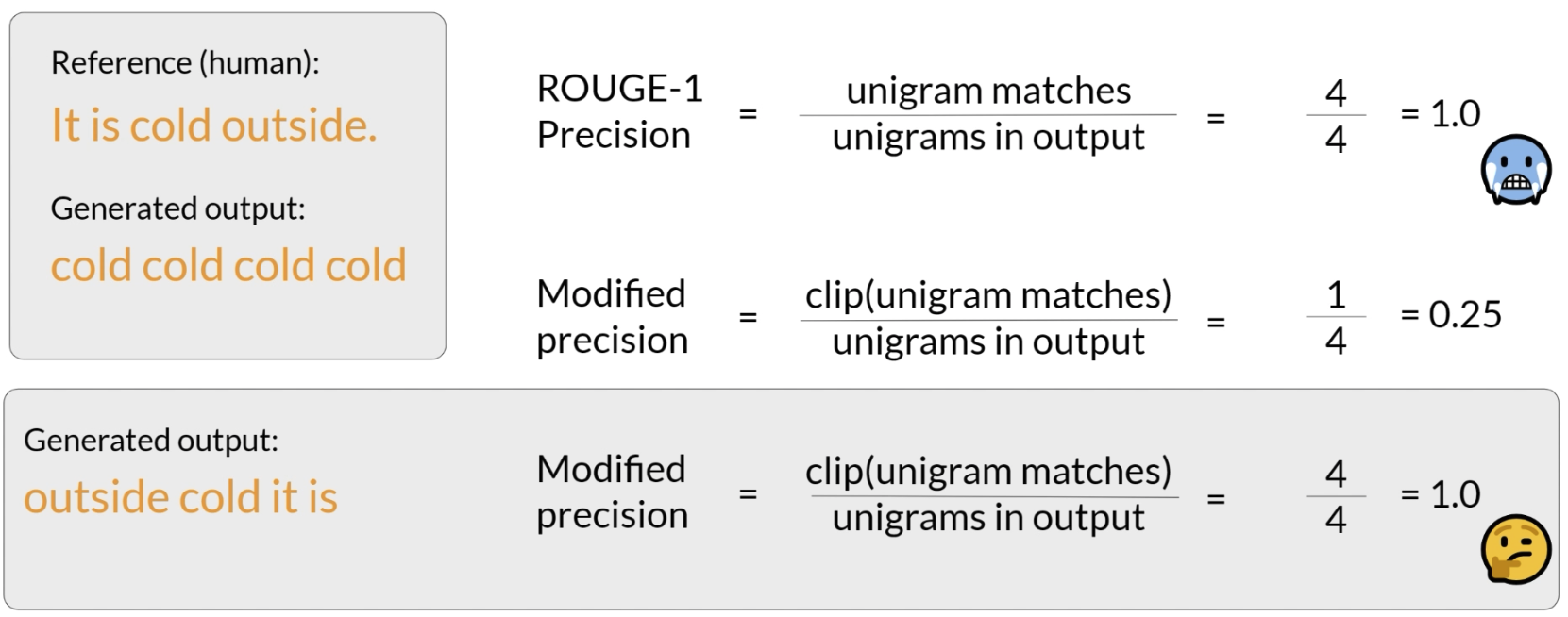
ROUGE-1 基于 unigram 匹配,计算 reference 和 generated output 之间的 recall、precision 和 F1。它只关注单个词是否匹配,不考虑词序。
为了进一步考虑局部词序关系,可以使用 ROUGE-2。它基于 bigram 匹配,也就是将相邻两个词作为一个单位进行比较,因此比 ROUGE-1 更严格。

除了 unigram 和 bigram,还可以使用 ROUGE-L。ROUGE-L 基于 longest common subsequence (LCS),能够在一定程度上反映句子整体结构和顺序信息。
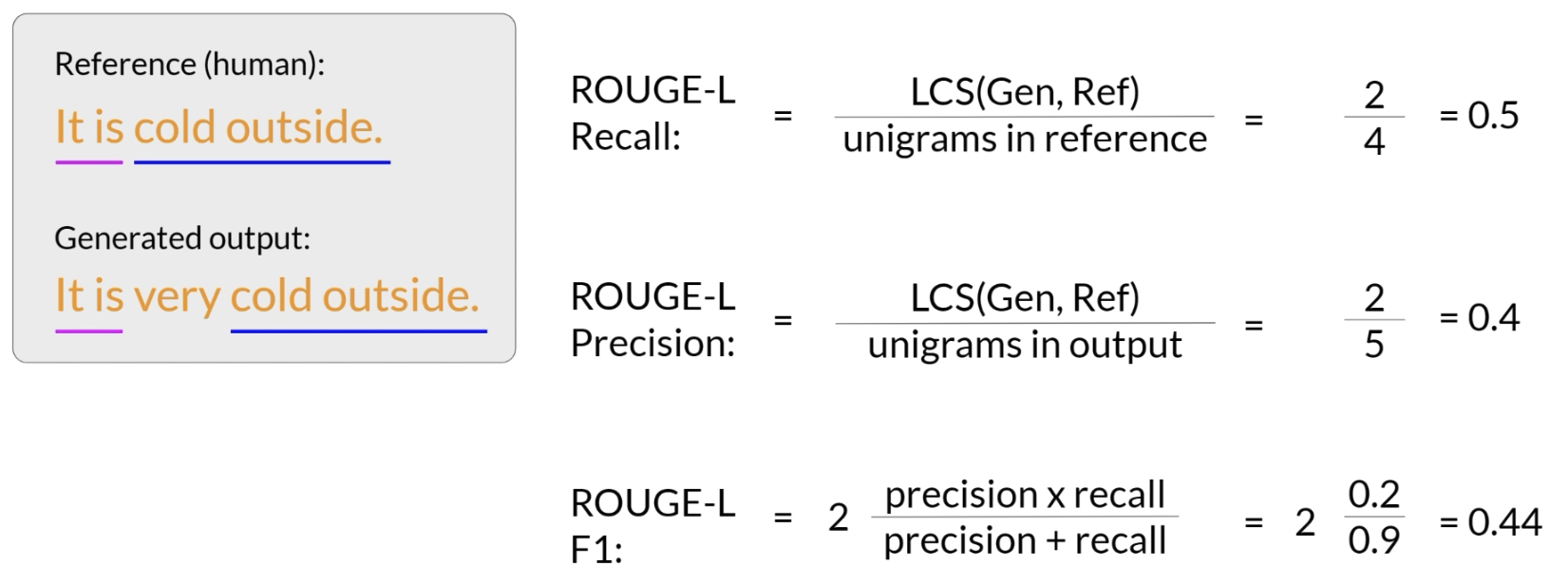
不过,ROUGE 也有局限。例如,如果模型重复输出某个词很多次,或者只是把正确词打乱顺序,分数仍可能看起来不错。因此它更适合作为诊断性指标,而不是唯一的最终评估标准。
BLEU 主要用于 machine translation。它通过综合多个 n-gram size 下的 precision 来评估 generated translation 与 human reference 之间的接近程度。通常来说,generated output 越接近 human reference,BLEU score 就越高。

2. Benchmarks
除了 ROUGE 和 BLEU 这类简单自动指标,还可以使用 benchmarks(基准测试)来更全面地评估LLM的能力。一个好的evaluation dataset应该能够测试模型的特定能力,例如 reasoning(推理)、common sense knowledge(常识知识),或者评估潜在风险,例如 disinformation(虚假信息)和copyright infringement(版权侵权)。同时,评估数据最好是模型在训练中没有见过的数据,这样才能更准确地反映模型的真实能力。
有一些课程里列举出来了的benchmark:
- GLUE:较早的自然语言理解基准,包含 sentiment analysis、question answering 等任务
- SuperGLUE:GLUE 的升级版本,任务更难,更强调 reasoning 和 reading comprehension
- MMLU:面向现代 LLM 的基准,测试模型在数学、历史、计算机、法律等多个学科上的知识和 problem-solving ability
- BIG-bench:覆盖非常广,从语言、常识推理到生物、物理、社会偏见、软件开发等都有
- HELM:一个更全面的评估框架,不只关注 accuracy,还会衡量 fairness(公平性)、bias(偏见) 和 toxicity(有害性)
简单指标适合做局部诊断,而 benchmark 更适合用来整体比较不同 LLM 的能力和风险。
Parameter-Efficient Fine-Tuning (PEFT)
1. PEFT overview
为什么在 LLM 上进行full fine-tuning往往成本很高,因为训练时除了模型参数本身,还需要额外存储optimizer states、gradients 和 activations,这会带来很大的显存和存储开销。相比之下,PEFT只更新少量参数,或者在冻结原始模型参数的基础上增加新的可训练组件,因此训练成本更低,也更适合资源受限的场景。与此同时,PEFT 也更不容易出现catastrophic forgetting,并且更适合为多个任务分别保存和切换不同的微调结果。
PEFT 的优势主要有三点:
- 降低训练成本:只训练少量参数,显存需求更小,很多情况下单张 GPU 就可以完成
- 减轻 catastrophic forgetting:因为大部分原始参数保持不变,所以不容易像 full fine-tuning 那样把模型“练偏”
- 更适合多任务场景:每个任务只需要保存一小组额外参数,推理时再和原始模型组合使用,不需要为每个任务保存一个完整新模型
PEFT 方法大致分成三类:
- Selective methods:只微调原模型中的一部分参数或层
- Reparameterization methods:通过低秩变换减少需要训练的参数,典型方法是 LoRA
- Additive methods:冻结原模型,额外加入新的可训练组件,例如 adapters 或 soft prompts
2. LoRA (Low-Rank Adaptation of Large Language Models)
LoRA 是一种常见的PEFT方法,目标是在不更新整个大模型的情况下,尽量用更少的可训练参数完成微调。基本思路就是冻结原始模型参数,只额外训练一组低秩矩阵来表示权重更新。这样可以显著降低训练所需的显存和计算成本。
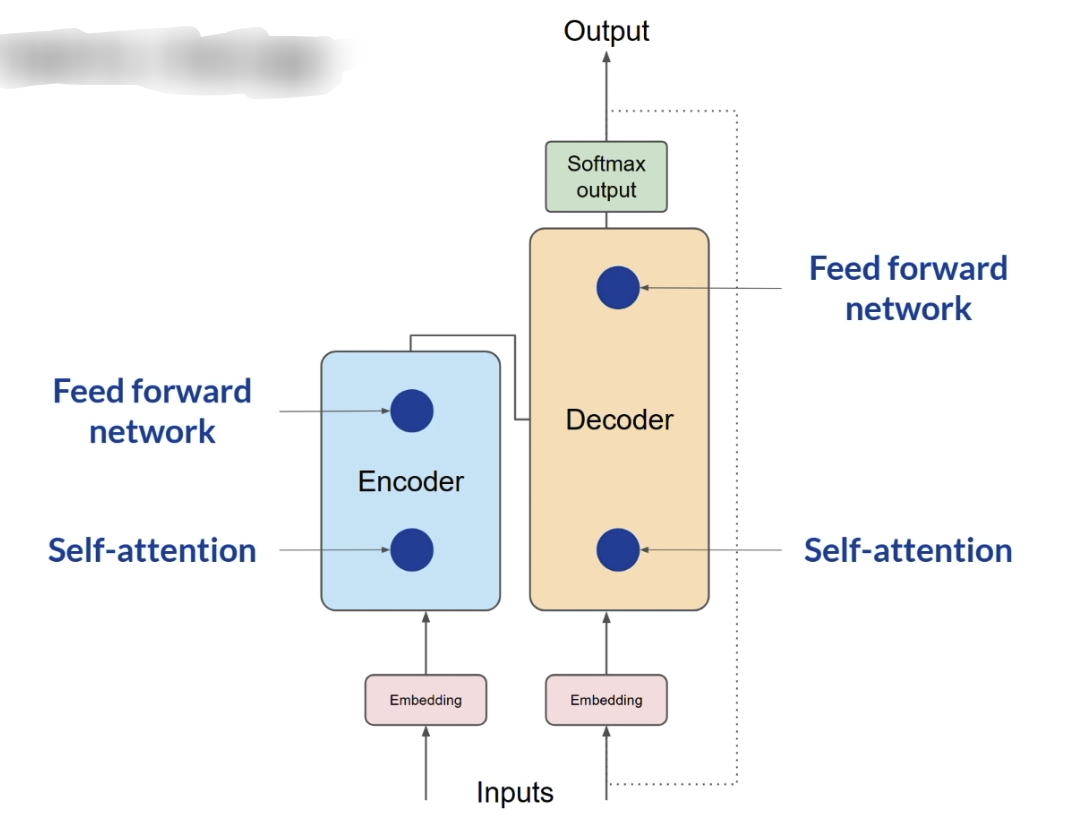
在 full fine-tuning 中,模型的所有参数都会被更新,因此训练成本很高;而在 LoRA 中,原始权重保持不变,只在某些层旁边加入两个较小的低秩矩阵,并只训练它们。
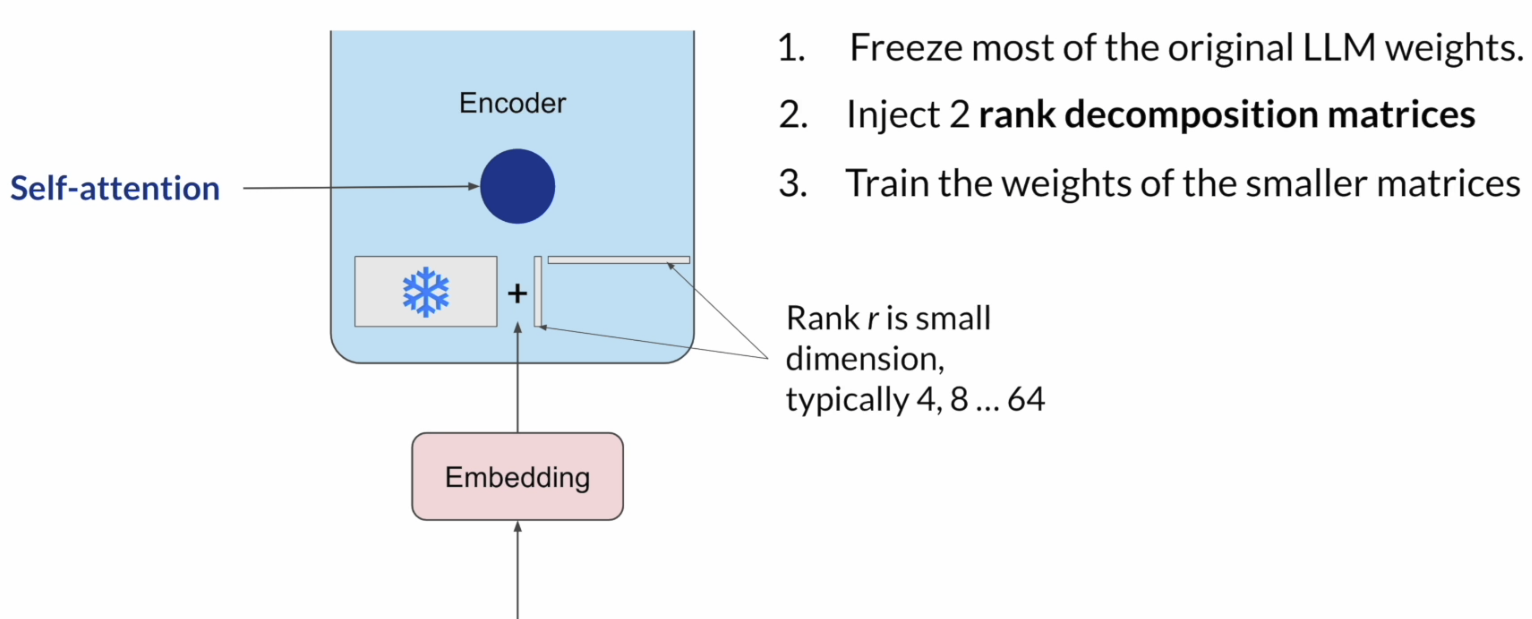
推理时,再把这两个小矩阵相乘得到更新项,加回原始权重中,从而得到适配当前任务的模型参数。
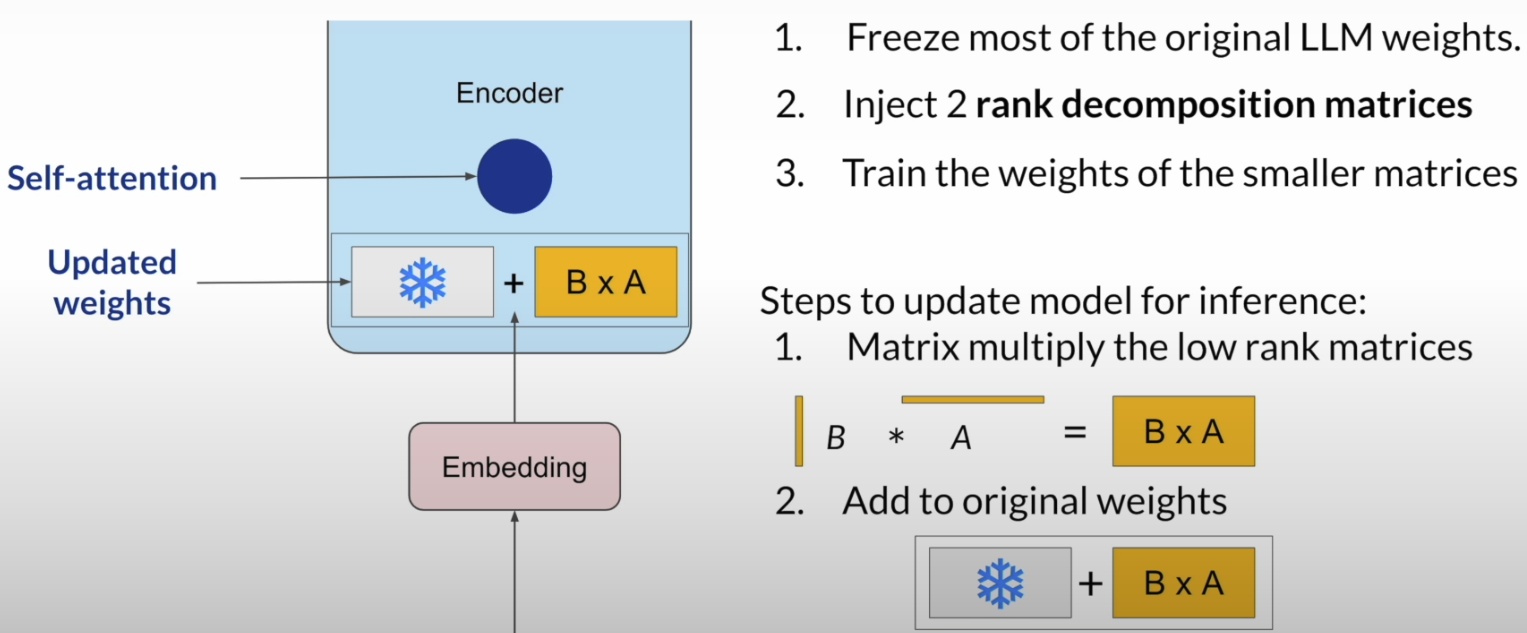
LoRA 的一个关键点是,它并不是直接学习一个完整的大权重更新矩阵,而是用两个小矩阵去近似这个更新。因此,当 rank r 足够小的时候,需要训练的参数量会大幅下降。课程中的例子里,原始权重矩阵大小为 512 × 64,共有 32,768 个参数;如果使用 rank = 8 的 LoRA,只需要训练 4,608 个参数,减少了 **86%**。这说明 LoRA 能在保持效果的同时大幅降低训练成本。

LoRA 通常应用在 Transformer 的 self-attention layers 上,因为这些部分对模型行为影响很大,而且这样做往往已经能够带来明显的性能提升。相比 full fine-tuning,LoRA 的优势在于:
- 更省显存
- 更省存储
- 更容易在单张 GPU 上完成训练
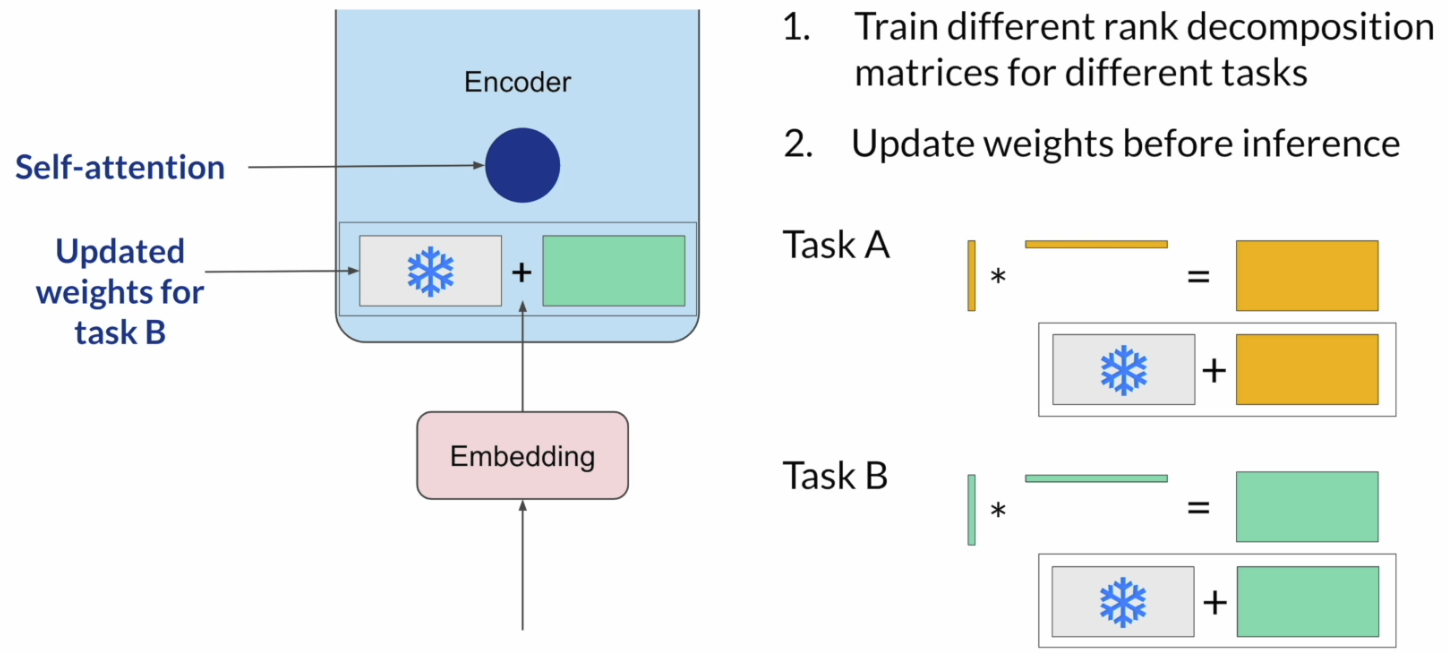
- 更适合为不同任务分别保存和切换适配结果
对于多任务场景,只需要为每个任务保存一组很小的 LoRA 参数,而不需要保存多个完整模型。
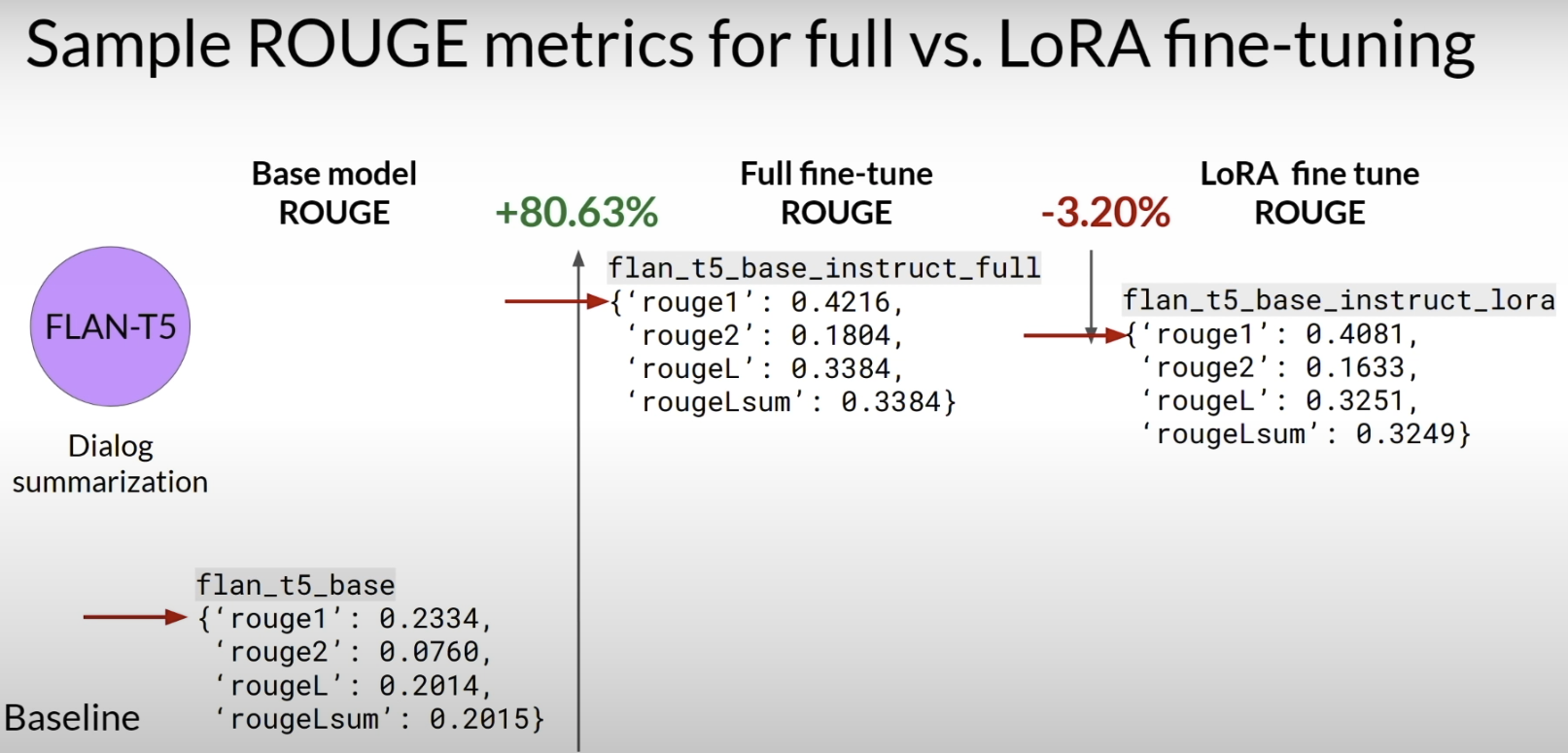
从效果来看,LoRA 通常比 full fine-tuning 略差一点,但差距往往不大。课程中给的 dialog summarization 例子表明,LoRA fine-tuning 的 ROUGE 分数虽然略低于 full fine-tuning,但已经明显优于 base model,因此在很多实际场景中,这种“用更低成本换接近效果”的 trade-off 是非常值得的。
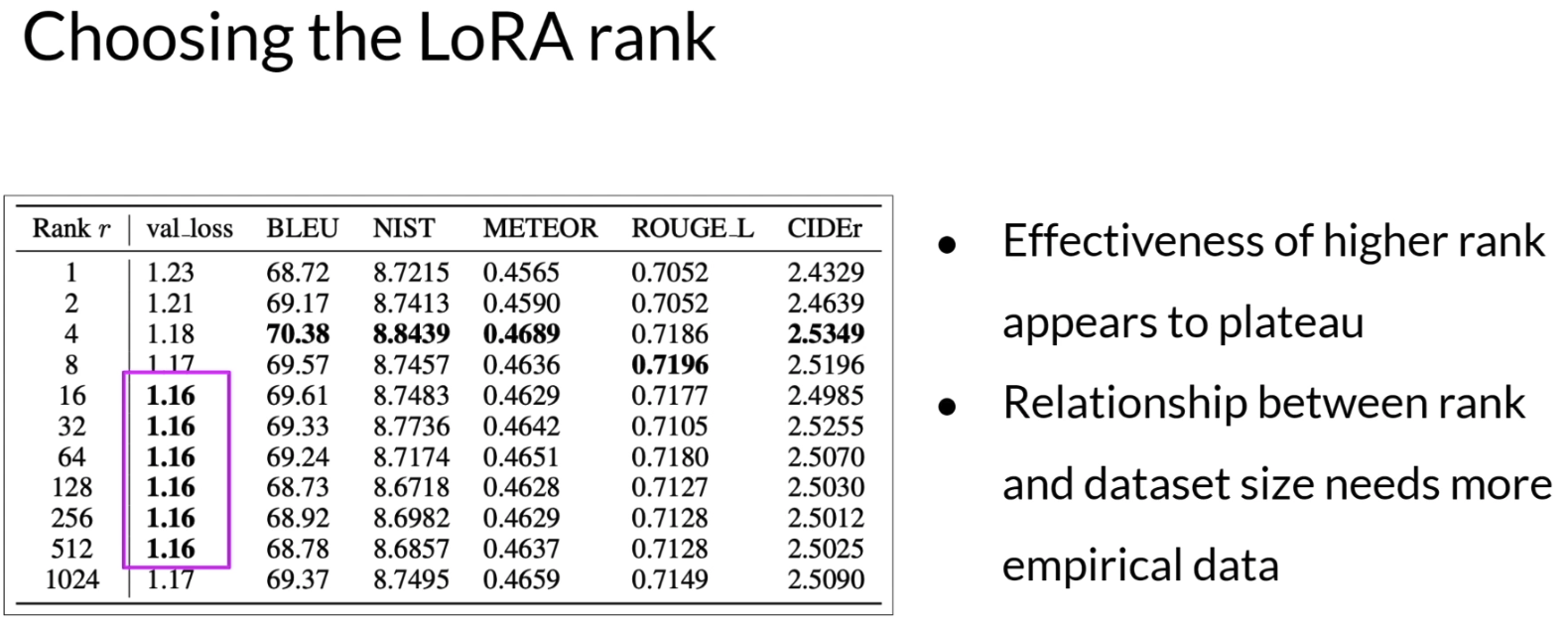
LoRA 中的rank是一个重要超参数。rank 越小,可训练参数越少,训练成本越低。但如果 rank 太小,也可能限制模型效果。课程中给出的经验是,4 到 32 往往是比较实用的范围,更大的 rank 不一定会持续带来性能提升。
3. Soft prompts
Prompt tuning 也是一种 PEFT 方法,但它和 LoRA 不一样。LoRA 是尽量少改模型里的参数,而 prompt tuning 干脆不改模型权重,只是在输入前面加上一小段可以训练的 soft prompt,让模型更适应某个特定任务。
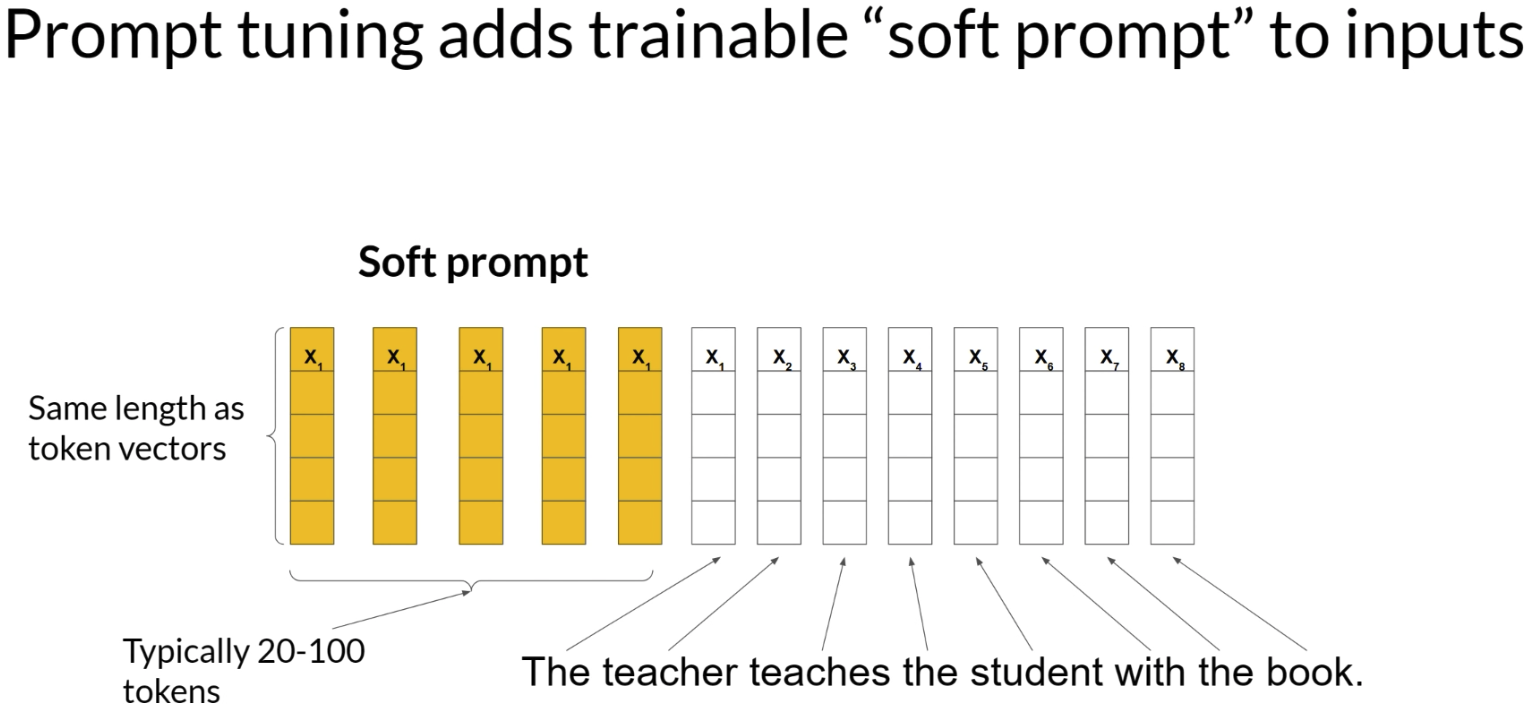
prompt tuning 不等于 prompt engineering。prompt engineering 是人为的去改提示词,比如换一种说法、加几个例子、做 one-shot或者few-shot;prompt tuning 则不是手工写 prompt,而是让模型通过训练,自己学出一组最适合这个任务的“提示向量”。
这些 soft prompt 不是正常的自然语言单词,而是一组在 embedding space 里的连续向量。它们和普通 token embedding 维度一样,但不一定对应词表里的真实词。一般用 20 到 100 个 virtual tokens,就可能让模型取得不错效果。
从训练方式上看,prompt tuning 和 full fine-tuning 的差别很直接。在 full fine-tuning 里,训练时会更新整个模型的参数。而在 prompt tuning 里,模型本体是冻结的,真正被更新的只有前面那一小段 soft prompt。
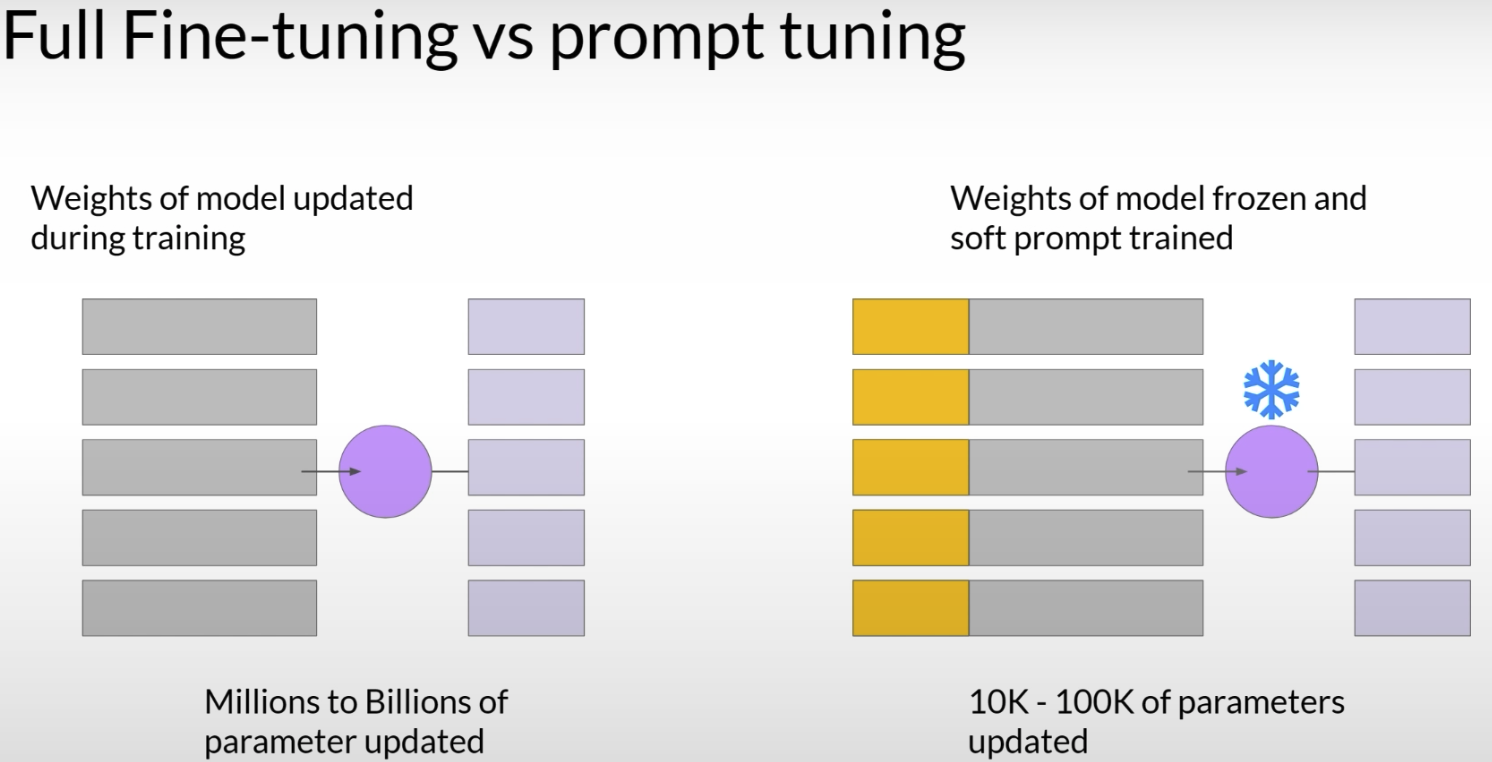
所以 prompt tuning 最大的特点就是:参数量特别小,训练成本也特别低。full fine-tuning 可能要更新 millions 到 billions 的参数,但 prompt tuning 通常只需要训练 10K–100K 量级的参数。它不是去重新训练一个大模型,而是给这个大模型外挂一小段可训练前缀。
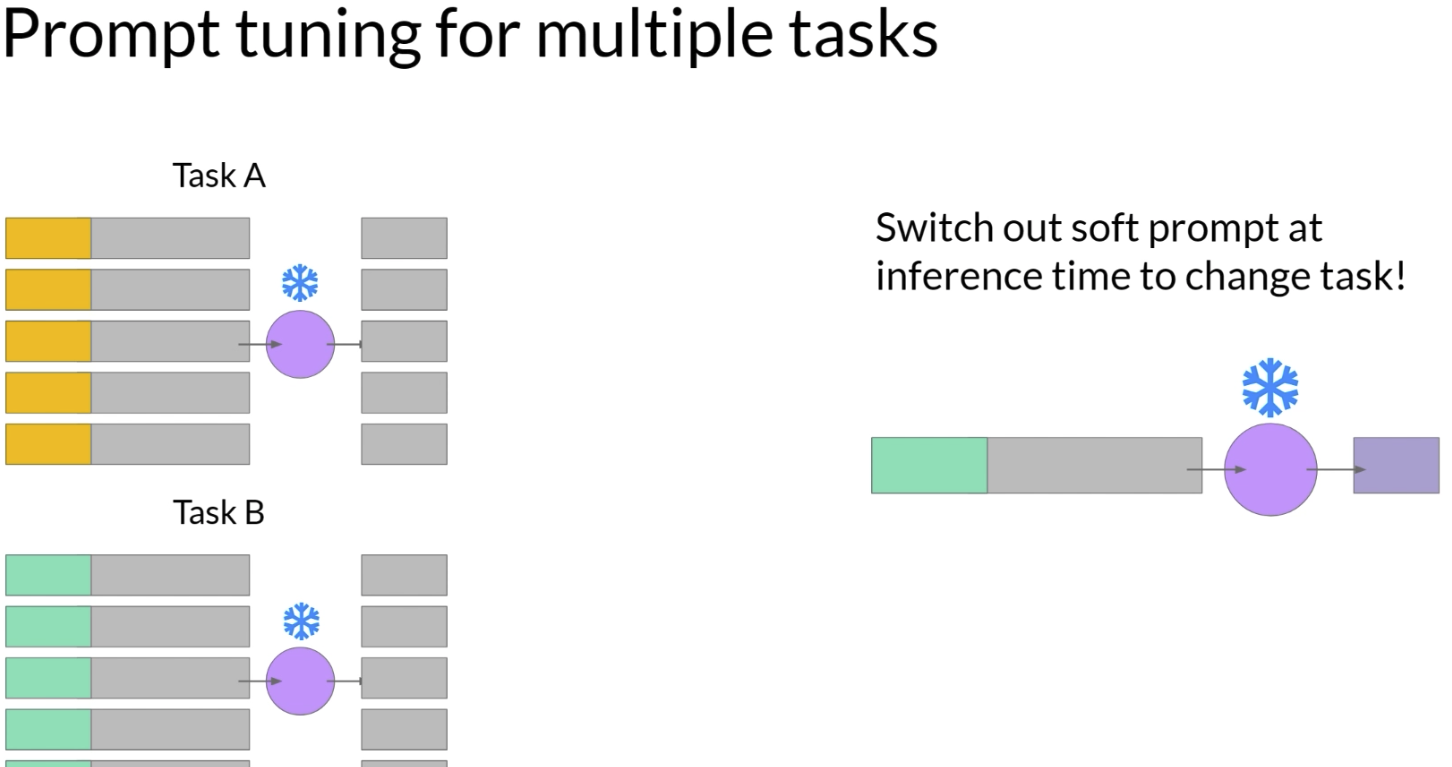
它还有一个很实用的地方,就是适合 multiple tasks。不同任务可以分别训练不同的 soft prompts,推理的时候直接把前面的 soft prompt 换掉就行,不需要重新换整个模型。这个思路和 LoRA 有点像,都是一个底座模型 + 多个小任务模块。
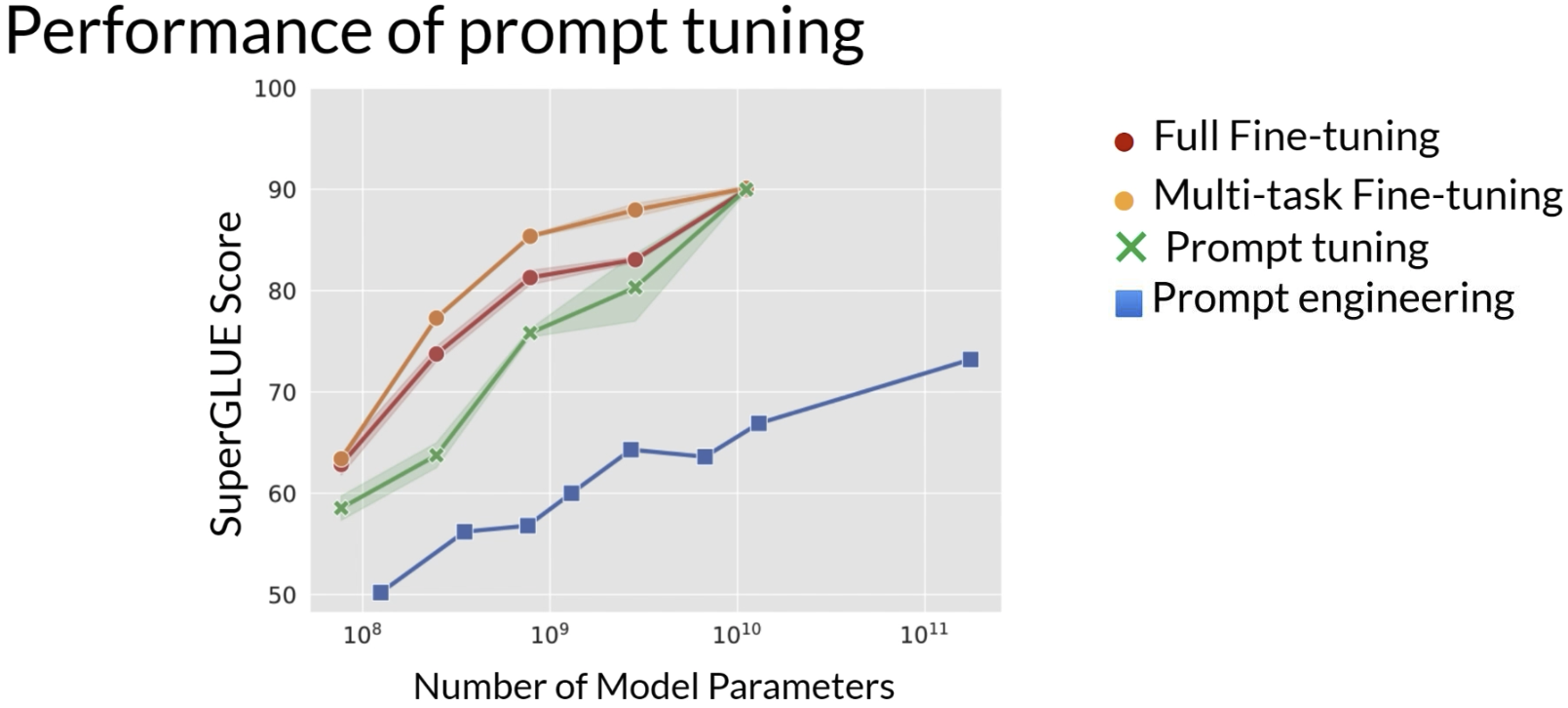
从效果上看,prompt tuning 并不是永远都和 full fine-tuning 一样强。课程里给出的结论是,在小模型上,它通常不如 full fine-tuning,但模型越大,prompt tuning 的效果就越接近 full fine-tuning。
下图里用的是 SuperGLUE 分数。绿色线是 prompt tuning,红色线是 full fine-tuning,蓝色线是单纯 prompt engineering。可以看出来,prompt tuning 明显比只靠手工写 prompt 更强,但是会随着模型参数的增多越来越接近 full fine-tuning。
不过 prompt tuning 也有一个特点,就是可解释性比较弱。因为 soft prompt 不是实际单词,所以你很难直接读懂,说它到底学到了哪一句自然语言。但这些 soft prompt 在 embedding space 里的最近邻通常会形成比较紧的语义簇,说明它们并不是瞎学,而是真的学到了一些和任务相关的表示。