
【笔记】吴恩达Generative AI with Large Language Models --- Week1
本篇为学习吴恩达DeepLearning.AI平台下《Generatvie AI with Large Language Models》笔记
课程:DeepLearning.AI — Generative AI with Large Language Models
链接:Generative AI with Large Language Models
Week1: Generative AI user cases, project lifecycle, and model pre-training
Transformer Architecture
1. LLM 与传统机器学习的输入输出方式差异
和传统机器学习常见的“固定特征输入 → 预测标签/数值”不同,LLM 通常直接接收自然语言prompt(提示词)作为输入,然后生成 completion(续写/补全)作为输出。
- Prompt:你给模型的上下文、指令、问题
- Completion:模型根据 prompt 继续生成的文本(通常是逐 token 生成)
2. 为什么早期 RNN 系列模型不够好
早期 RNN/LSTM/GRU 虽然能处理序列,但在长距离依赖(long-range dependency)上仍然吃力,信息要一步步在时间维传播,长句子里早期信息容易衰减或“忘掉”,也就是没办法那么好的处理好memory。但语言本身有大量歧义和跨词关系,只看相邻词的局部模式往往不够。
例如:
“The teacher taught the student with the book.”
这里的歧义是:with the book 修饰 teacher 还是 student?也就是到底是谁“带着书”。

3. Transformer:核心改变是什么
2017 年论文《Attention Is All You Need》提出 Transformer 结构后,主流 LLM 的路线就基本确立了。现代大模型的核心骨架仍然是 Transformer,只不过在工程细节上进行了一些演进。
Transformer 带来的关键转变:模型不再主要依赖“按顺序传递隐藏状态来记忆”,而是通过Attention(注意力)机制,让每个 token 可以直接“查看”序列里其它 token,从而更擅长学习远距离依赖与结构关系。
4. Transformer Architecture
Transformer 相比 RNN 的关键提升来自 self-attention。它让模型在处理一个 token 时,可以同时考虑 input sequence 里所有 token 的 relevance,而不是只依赖邻近 token 或一步步传递的 memory。这种能力对处理歧义句子非常重要,例如 with the book 到底在修饰 teacher 还是 student。
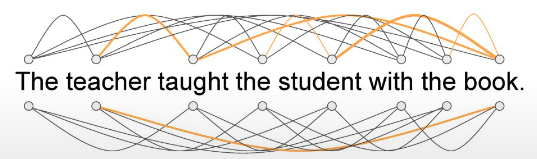
self-attention 会给 token 之间分配 attention weights。权重越大,表示当前 token 在更新表示时更依赖另一个 token。attention map 可以用来可视化这些 weights,帮助理解模型在关注哪些关系。attention weights 是在 training 中 learned 出来的,不是人为指定。
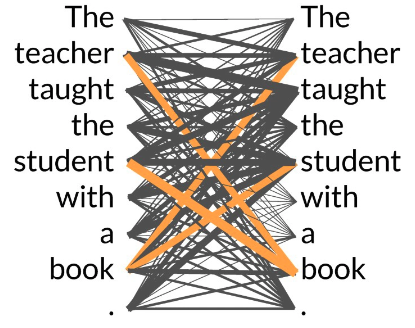
在示意图里,book 对 teacher 和 student 的连接更强,这体现了模型在尝试捕捉上下文关联,从而帮助消解歧义。
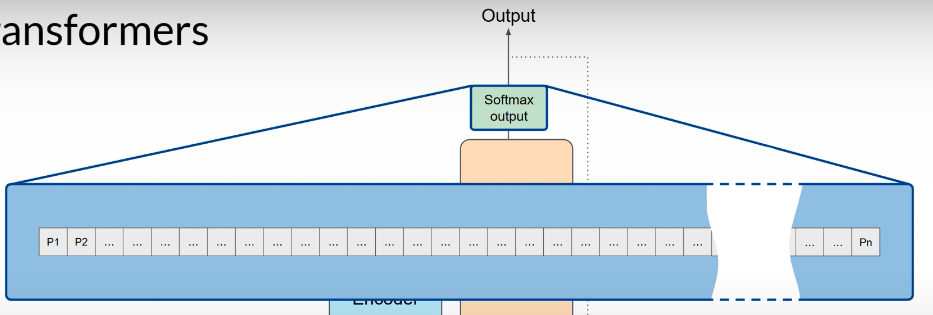
从整体结构看,经典 Transformer 架构来自《Attention Is All You Need》,inputs 在底部,outputs 在顶部。它分为 encoder 和 decoder,两者配合工作并共享很多相似模块。很多 LLM 使用 decoder-only,但这里先用 encoder-decoder 的图来理解整条处理流程。
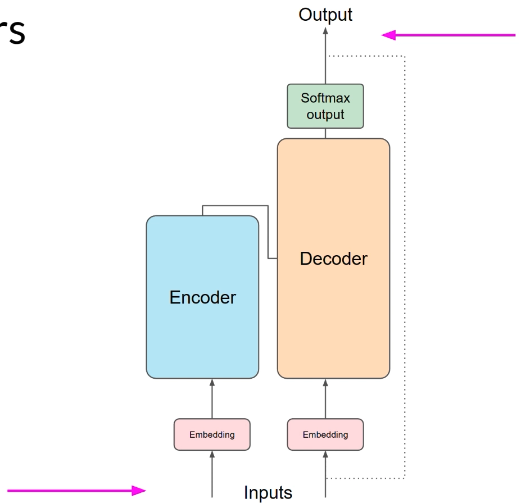
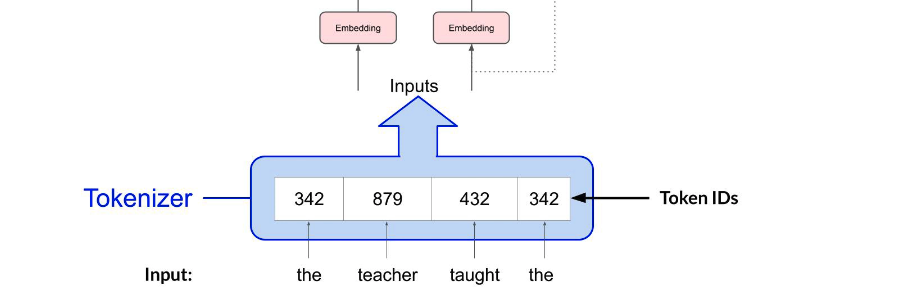
模型只处理 numbers,不直接处理 words,所以第一步是 tokenization,把 text 转为 token IDs。token IDs 可以对应 complete words,也可以对应 parts of words。关键点是 tokenizer 一旦用于 training,generation 时必须保持一致。
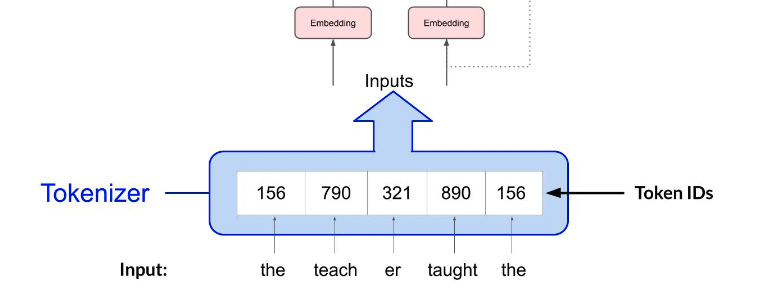
真实 LLM 更常用 parts of words 的方式,一个单词可能被切成多个 token。这样 vocabulary 不需要无限大,也能覆盖新词、专有名词和词形变化。
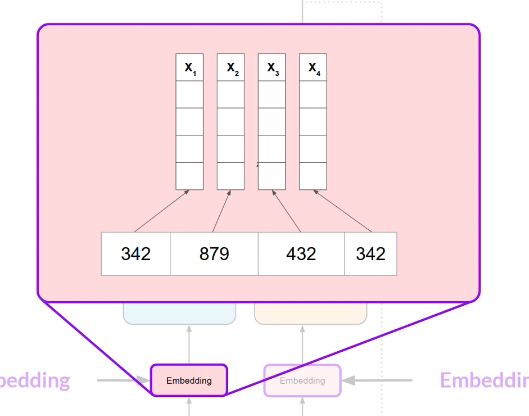
token IDs 接下来进入 embedding layer,变成 embedding vectors。embedding 是 trainable vector embedding space,每个 token ID 映射到一个 multi-dimensional vector。通常,这些 vectors 会逐渐 encode token 的 meaning 和上下文信息

从这里开始,模型处理的就不再是文字,而是一串向量序列。每个 token 对应一个 vector,组成 input sequence 的向量表示
把 embedding 想象成一个向量空间,相近的 token 往往更接近。相似性常用 angle 的直觉来理解,这也是模型用数学方式描述language的一个切入点。
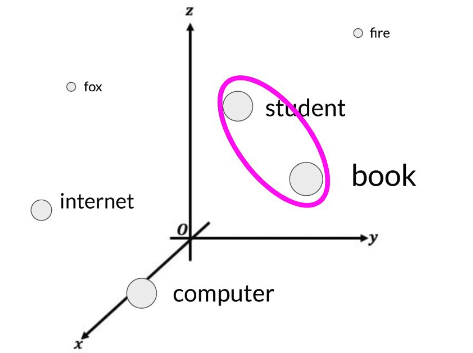
Transformer的计算可以并行进行,为了保留 word order,需要加入positional encoding。通常是 token embeddings 与 positional encodings 相加,然后送入 self-attention layer,让模型在建模关系时仍然知道每个 token 的相对位置。
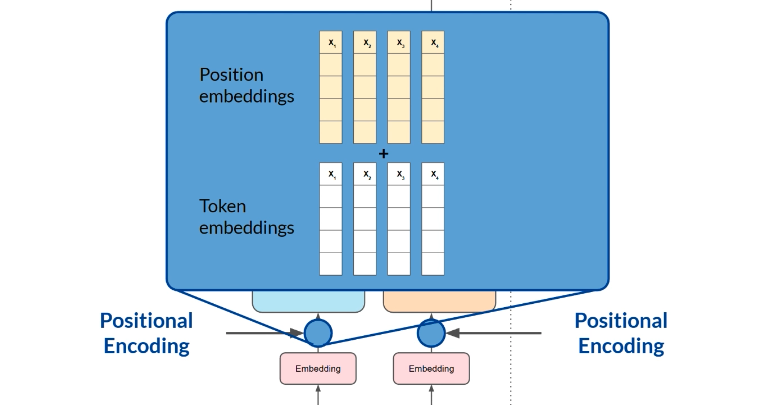
self-attention 不只做一次,实际是 multi-headed self-attention。多个 heads 并行、独立学习。head 数量随模型而变,常见在 12 到 100 的范围。不同 head 会学到 language 的不同 aspect,但你不会提前指定它们学什么,weights 从随机初始化开始,在训练中逐渐分化。
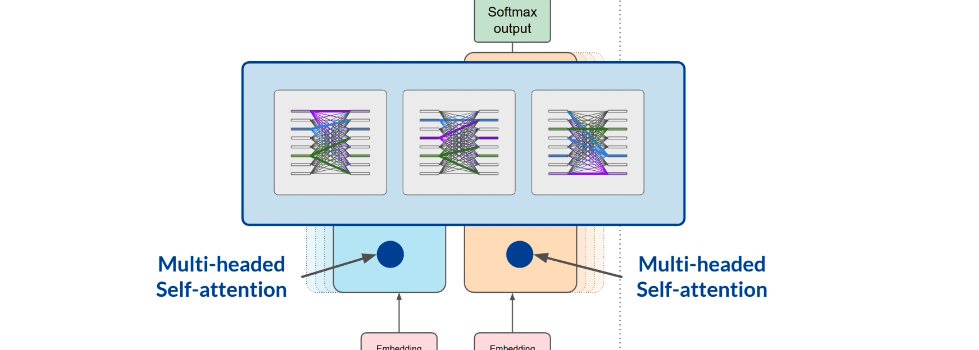
在 attention 之后,输出会经过 fully connected feedforward network。最终模型得到 logits,对 vocabulary 里每个 token 给出一个 score,表示它作为 next token 的相对可能性。
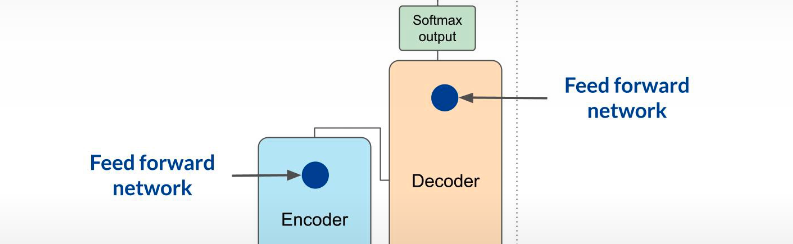
logits 再经过 softmax 变成 probability distribution。因为 vocabulary 很大,这里会产生很多 scores,其中某个 token 通常最高,代表最可能的 predicted token。后续还会介绍不同的 decoding methods,用来改变最终从这个 distribution 里选择 token 的方式。
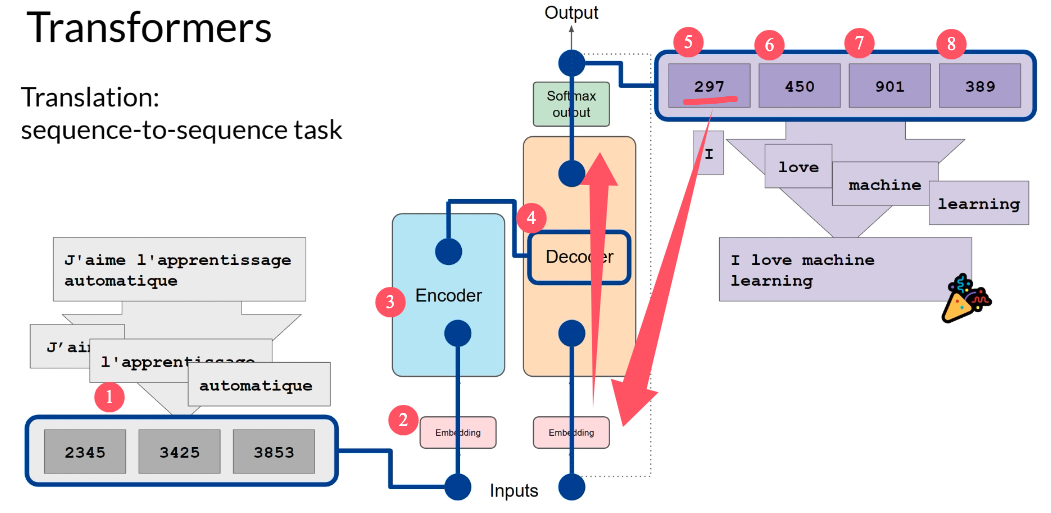
Generating Text with Transformer
一个例子,把法语“J’aime l’apprentissage automatique”翻译成英文来描述的过程,transformer是怎么操作的。
先把它切成 tokens,并转成token ids(图左下角的数字)。这些 ids 进入Embedding层,变成向量后送进Encoder。Encoder 经过多层 Multi-Head Self-Attention + Feed Forward,输出一组更“懂语义和结构”的表示(contextual representations)。
然后进入Decoder:先喂一个start-of-sequence token作为起点(例如此处为297)。Decoder 每一步用masked self-attention看自己已经生成的内容,同时通过cross-attention读取 Encoder 的输出(相当于“对着输入句子对齐理解”)。接着通过Softmax得到下一个 token 的概率分布,选出一个 token(图右上角的数字),再把它回传作为下一步输入。
这样循环生成,直到预测到 end-of-sequence token,最后把输出 token ids de-tokenize 回文本,就得到英文翻译,比如 “I love machine learning.”
总的来说,也就是Encoder用来把输入序列编码为输入的结构和含义的深层含义,而decoder从输入的token触发器开始工作,使用编码器提供的这些结构来理解并生成新的token,这一过程会一直循环直到生成最后一个token。
Encoder Only Models
只有 Encoder,没有 Decoder。它把输入序列编码成上下文表示;在“不做额外改造”的情况下,输出和输入长度通常一致,所以纯 seq2seq 用得少一些。加一些任务头(classification head)后很适合做分类类任务,比如 sentiment analysis。代表:BERT。
Encoder Decoder Models
经典 Transformer 全家桶:Encoder 先理解输入(deep representation),Decoder 在 Encoder 的上下文引导下 autoregressive 逐 token 生成输出,所以非常适合sequence-to-sequence,而且输入输出长度可以不同(比如 translation、summarization)。也可以训练得更大用来做更通用的生成。代表:BART、T5。
Decoder Only Models
只有 Decoder,通过 autoregressive 方式从前文预测下一个 token(next-token prediction),现在最常见、最主流的路线之一。规模上去后能对很多任务做 zero-shot / few-shot 泛化(问答、写作、代码、总结等)。代表:GPT family、BLOOM、Jurassic、LLaMA。
Prompting and Prompt Engineering
这一节在课程中主要就是讲了一些概念,我在之前发过一篇博客,是专门针对prompt engineering的,也是deeplearning.ai中的课程,主要是一些prompt的设计思路、概念,以及实现了一个聊天机器人:模型提示词—Prompt Engineering(提示工程)
prompt:你喂给模型的输入文本
inference:模型“正在生成”的过程
completion:模型最终输出的文本
context window:模型一次能使用的总文本容量(prompt + 示例 + 其它上下文都会占用)
prompt engineering:为了拿到更理想的输出,不断调整 prompt 的措辞/结构/约束的迭代过程
in-context learning:把示例或额外数据直接放进 prompt,让模型在当前上下文里“学会”任务和输出格式
- zero-shot:不给示例,直接让模型做任务
- one-shot:给 1 个示例
- few-shot:给多个示例(最好覆盖不同类别/输出形式,比如正面+负面)

经验结论:大模型通常 zero-shot 就挺强;小模型更依赖 one-shot / few-shot 才能跟上指令和格式
限制与取舍:示例越多越吃 context window;如果加到 5–6 个例子还不稳定,通常该考虑 fine-tuning(用新数据做额外训练)
规模效应:参数更多的模型更容易泛化到多任务;小模型往往只擅长与训练分布相近的少数任务,需要多试模型匹配场景
Generative Configuration
同样主要是一些关于大模型的参数的概念:
- Inference-time configuration parameters:推理阶段可调的参数,用来影响输出(和训练时 learned parameters 不是一回事)
- max_new_tokens:限制最多生成多少个新 token(是“上限”,不保证一定生成到这个数;可能提前遇到 stop condition / EOS 就结束)
- softmax output:每一步都会得到一个“词表上的概率分布”,下一 token 从这里决策出来
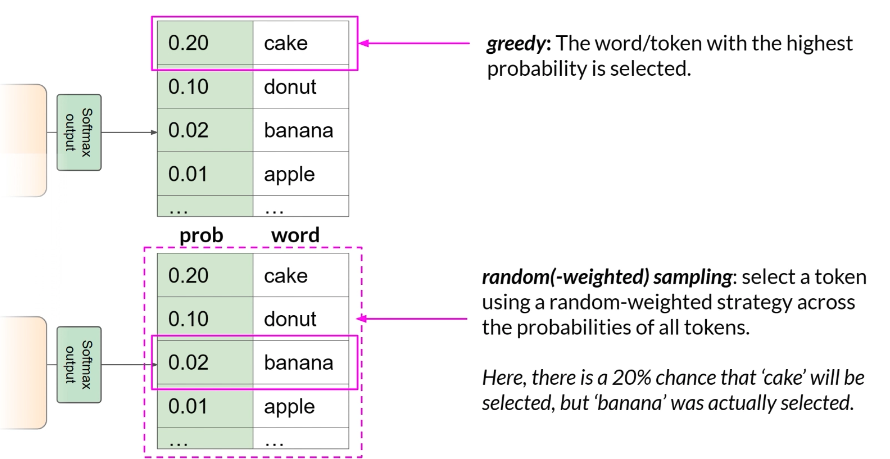
- greedy decoding(默认常见):每步都选概率最高的 token
- 优点:简单、短文本常常够用
- 缺点:容易出现重复词/重复片段,文本可能变得机械
- random sampling(do_sample=true):按概率分布“抽样”选 token,而不是永远选最大值
- 优点:更自然、更有变化,减少重复
- 缺点:可能过于发散,跑偏到不合理内容
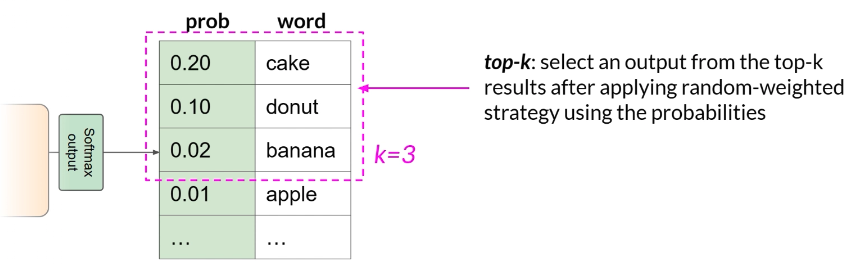
TopK sampling:只在概率最高的 K 个 token 里抽样(比如 K=3 就只在前三名里随机)
- 作用:保留随机性,同时避免选到很离谱的低概率词
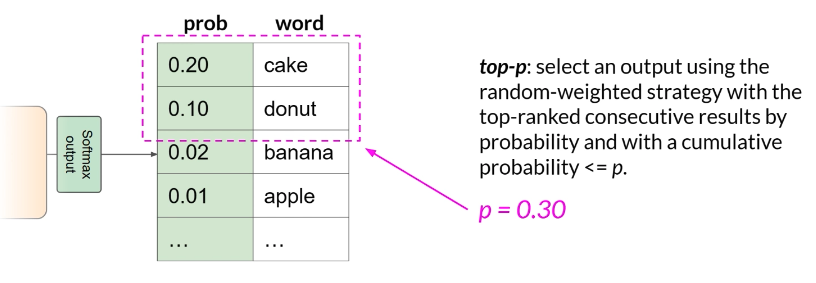
TopP sampling(nucleus sampling):选一个“累计概率不超过 P 的最小集合”来抽样(比如 P=0.3,就取累计到 0.3 为止的那些候选)
- 对比:TopK 控“候选数量”,TopP 控“候选概率质量”
temperature:调 softmax 概率分布的“尖锐/平坦”程度
- T < 1:分布更尖(更偏向少数高概率词),输出更稳、更贴训练分布
- T = 1:默认
- T > 1:分布更平(更多词有机会被选),输出更随机、更“creative”
- 区别点:TopK/TopP 是“裁剪候选”,temperature 是“改变分布形状”,会影响模型实际偏好

组合:想要“稳”→ 低 temperature +(可选)小 TopP/TopK;想要“活”→ 增加temperature + sampling + 合理的 TopP/TopK 防跑偏
Generative AI Project Lifecycle
生成式AI项目的生命周期主要为以下图所示
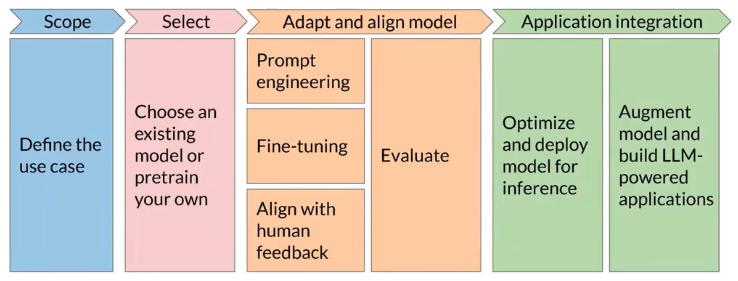
- Scope(Define the use case):先把需求“卡死”在一个清晰、尽量窄的范围里。想清楚 LLM 在你的应用里到底负责什么:是要通用生成/多任务,还是只做一个很具体的能力(比如 NER、分类)。范围越清楚,越省时间和算力成本。
- Select(Choose an existing model or pretrain your own):决定用现成 base model 还是从零训练。大多数场景先从现成模型开始;只有在数据/领域/约束非常特殊时才考虑 pretrain 自己的。
- Adapt and align model(Prompt engineering / Fine-tuning / Align with human feedback + Evaluate):
- 先用 prompt engineering / in-context learning 试到能用为止(成本最低、迭代最快)。
- 不够用再上 fine-tuning(监督微调,让模型更贴你的任务)。
- 上线前还要考虑 alignment(例如 RLHF,让行为更符合人类偏好/安全要求)。
- Evaluate 贯穿全过程:用指标/benchmark/人工评审反复测,整个阶段高度迭代(调 prompt → 评估 → 微调 → 再评估)。
- Application integration(Optimize & deploy for inference / Augment model and build LLM-powered applications):
- Optimize & deploy:把模型部署到你的基础设施里,并做推理侧优化(性能、成本、延迟、吞吐、稳定性)。
- Augment:承认 LLM 有硬伤(幻觉、数学/复杂推理不稳等),用外部能力补齐:检索、工具调用、规则、数据库、工作流等,把它变成真正可用的应用系统。
Pre-training large language models
Pre-training 可以理解成:模型先在海量无标注文本上做 self-supervised learning,学到语言的统计规律与结构。实际做应用时,一般默认你会先用现成的 foundation model,而不是从零训练。
选模型时有两个非常实用的习惯:
- 去 model hub(Hugging Face / PyTorch 这类)看 model cards:重点看它适合的任务、训练方式、已知限制(limitations),避免“模型看起来很强但用错场景”
- 建立一个intuition:不同 transformer 变体在 pre-training objective 上不一样,所以更擅长的任务也不一样
三类 Transformer 结构:objective → 能做什么
Encoder-only(auto-encoding)
训练目标是 Masked Language Modeling(随机 mask 一些 token,让模型补全重建句子,denoising)。因为能看前后文,所以更适合理解/分类类任务:sentiment analysis、NER、token classification。代表:BERT、RoBERTa
Decoder-only(autoregressive)
训练目标是 Causal Language Modeling / next-token prediction(只看左边,预测下一个 token)。更擅长生成;规模上去后也能 zero-shot 做很多任务。代表:GPT family、BLOOM
Encoder–Decoder(seq2seq)
输入输出都是文本的一段到一段,常用于 translation / summarization / QA。以 T5 为例,它用 span corruption:mask 掉一段 token,用 sentinel token 占位;decoder 再把被 mask 的片段按自回归方式生成回来。代表:T5、BART(注意是 BART 不是 BERT)
为什么“大多数时候不从零 pre-train”:算力与成本
训练大模型最常见的第一道墙是 GPU memory(OOM)。
- 1B 参数如果用 FP32(4 bytes) 存权重,光权重大约就要 4GB 显存

- 真正训练还要额外存 optimizer states、gradients、activations 等,显存开销会显著放大(所以训练比能加载难得多)
Scaling laws:不是“越大越好”,而是给定算力下怎么配更适合
研究里常讨论三件事的 trade-off:模型参数量、训练 token 数、compute budget。
经验结论之一是所谓 compute-optimal 的思路(Chinchilla 方向):很多超大模型可能参数太多但数据看得不够,更小的模型如果训练 token 更足,可能做到接近甚至更好的效果。课程里有提到,Chinchilla研究提出的compute-optimal思路:训练 token 数大约是参数量的 20×(数量级经验,实际会受数据质量、架构等影响)。
什么时候真的可能需要从零 pre-train:domain adaptation
如果目标领域词汇/表达方式需要很多专有名词(法律、医学、金融、科研等),现成通用模型可能:
- 不认识高频专业词,或用不对
- 同一个常见词在领域里含义不同(语义漂移)