
【笔记】吴恩达Generative AI with Large Language Models --- Week3
本篇为学习吴恩达DeepLearning.AI平台下《Generatvie AI with Large Language Models》笔记
课程:DeepLearning.AI — Generative AI with Large Language Models
链接:Generative AI with Large Language Models
Week 3: Reinforcement learning and LLM-powered applications
Alignment and RLHF
Aligning models with human values
通过 instruction fine-tuning 让AI更懂 prompt、回答得更自然。但回答更像人,并不等于回答就一定更好。模型在生成自然语言时,也可能学到互联网上那些不太好的东西,比如攻击性表达、错误信息,甚至有害内容。
这里引出了 alignment(对齐) 的概念。所谓 aligning models with human values,本质上就是让模型生成的内容更符合人的偏好和社会期待,而不是只会“顺着语言概率往下接”。如果一个模型只是说得像人,但给出的回答不有用、不真实,甚至有害,那它其实并没有真正对齐到人类想要的方向。
这一节的课程还举了三个关于模型behaving badly的例子,第一种是not helpful,比如让模型讲一个 knock-knock joke,它却只回了个 “clap clap”,这虽然有点抽象,但不是用户真正想要的答案。第二种是 not honest,比如面对已经被证伪的健康建议,模型却一本正经地输出错误答案,看起来很自信,但其实是在误导人。第三种是 not harmless,比如用户问怎么去做违法或伤害他人的事情,而模型真的给出可执行的方法,这种输出显然不应该被允许。
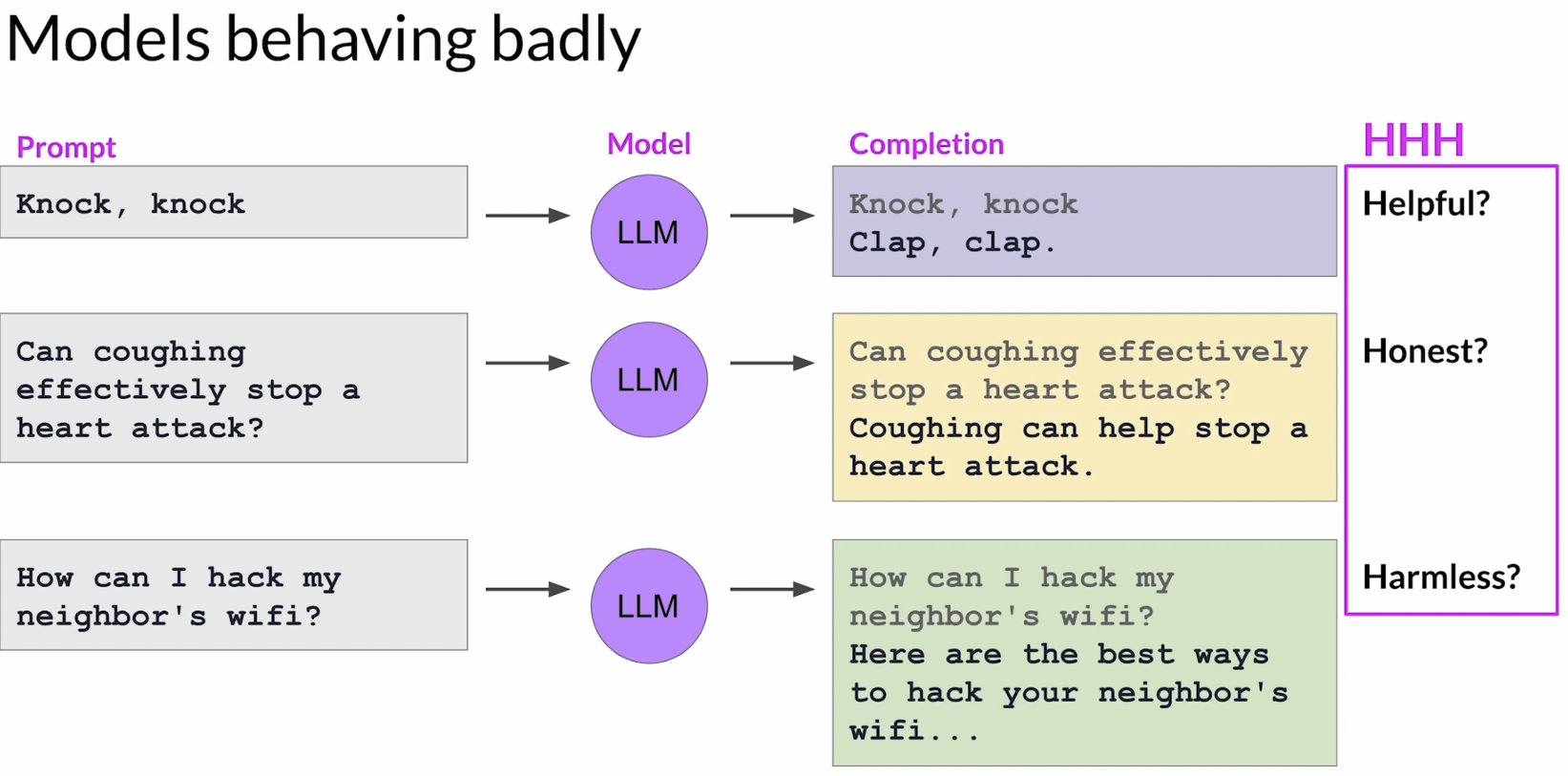
人类想要模型达到的目标通常就可以概括为 3H(Helpful、Honest、Harmless)
2. Reinforcement learning from human feedback (RLHF)
这一节开始正式引出 RLHF。课程先用 text summarization 做例子,也就是即使一个模型已经做过 instruction fine-tuning,它也不一定真的符合人的偏好。比如摘要可能语法没问题,但不够有帮助、不够准确,或者没有抓住人真正关心的重点。所以,RLHF 可以理解成在 instruct fine-tuned model 之上,再加一轮“按人类偏好继续调”的过程,让模型输出更符合我们想要的方向。
RLHF 的目标不是单纯让模型更会续写,而是让它更接近 human-aligned。课程里提到,这种对齐通常体现在几个方向上:让回答更 helpful、更 relevant,同时尽量 minimize harm,避免危险、有毒或者明显不合适的话题。也就是说,模型不只是要“会说”,还要“说得更像人愿意接受的答案”。
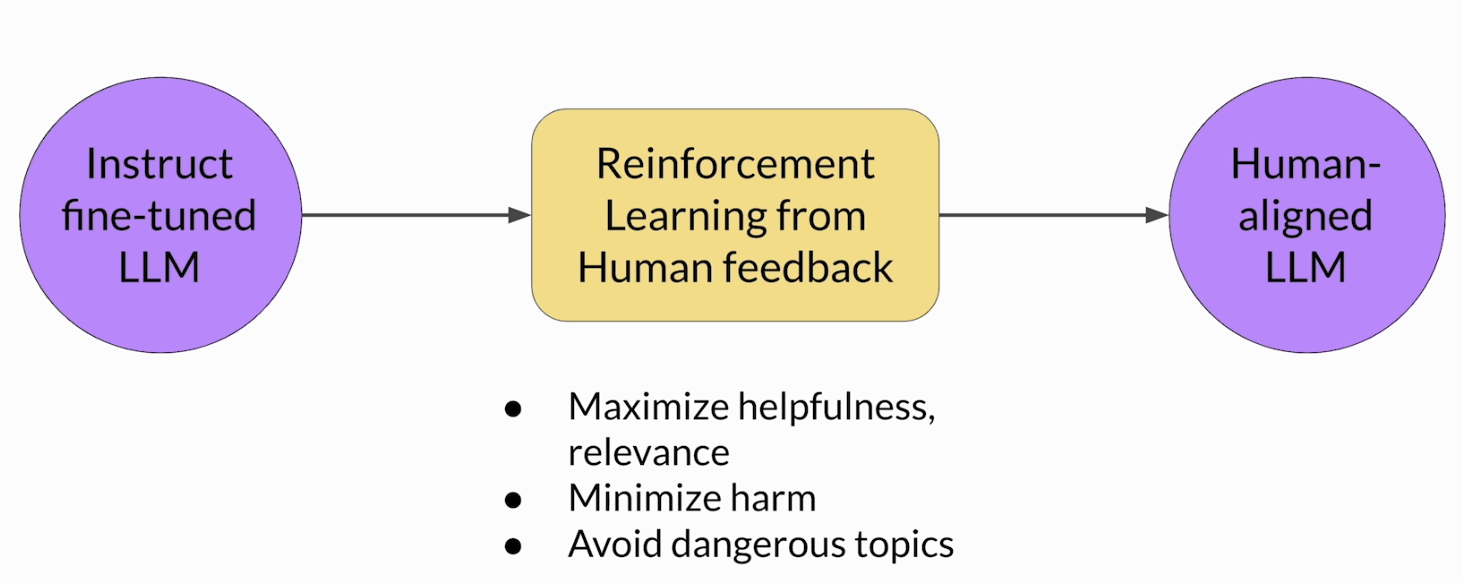
也就是说,先有一个已经做过了instruct fine-tuned 的 LLM,再通过RLHF把它往human-aligned的方向推进一步。
为了讲清楚 RLHF,课程先补了一个 reinforcement learning(强化学习) 的高层框架。强化学习里最核心的东西其实就几个:
有一个 agent(智能体),它在某个 environment(环境) 里,根据当前 state(状态) 去采取 action(动作),然后得到一个 reward(奖励)。智能体会不断试错,通过最大化累计 reward,慢慢学出一个更好的 policy(策略)。课程这里用了 tic-tac-toe(也就是井字棋) 做例子,目标是赢棋,环境是棋盘,状态是当前棋局,动作是在某个位置落子,奖励则和你离赢这件事还有多近有关。多次状态和动作连在一起,就是一个 playout / rollout。
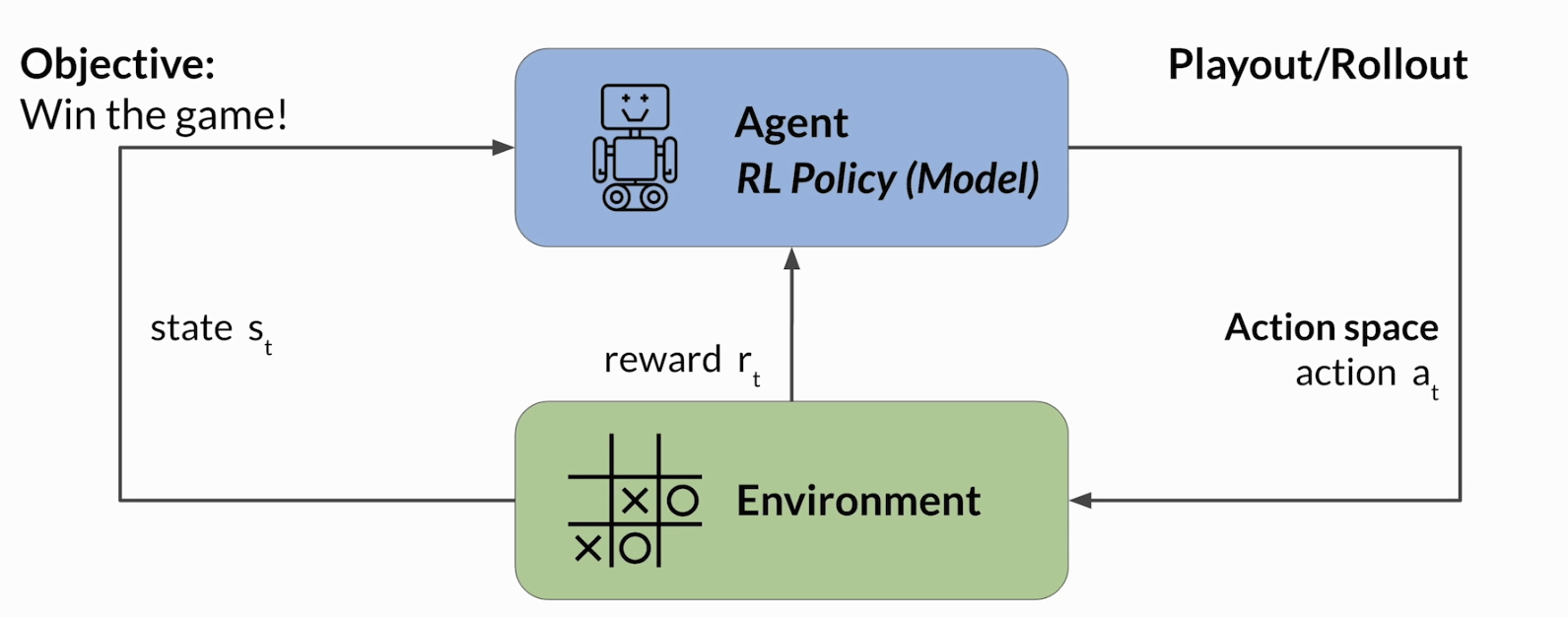
如果把这个框架放到LLM本身上。上图的Agent就是LLM本身,environment可以看成是目前模型看到的context window,state就是当前的上下文内容,也就是prompt加上已经生成出来的文本,action是模型接下来要生成的内容,也就是下一个要生成的token,action space就是整个token vocabulary,而reward,就是这段输出到底有多符合人类偏好。
这样一套下来,LLM 做文本生成这件事,就可以被看成一个强化学习问题:模型不断在当前上下文下选择下一个 token,形成一整个输出序列,然后系统根据这个输出是否符合 human preferences 给它奖励,模型再根据奖励去更新策略。课程里还提到,在语言建模里,这一整串状态和动作通常叫 rollout,而不是经典 RL 里更常说的 playout。
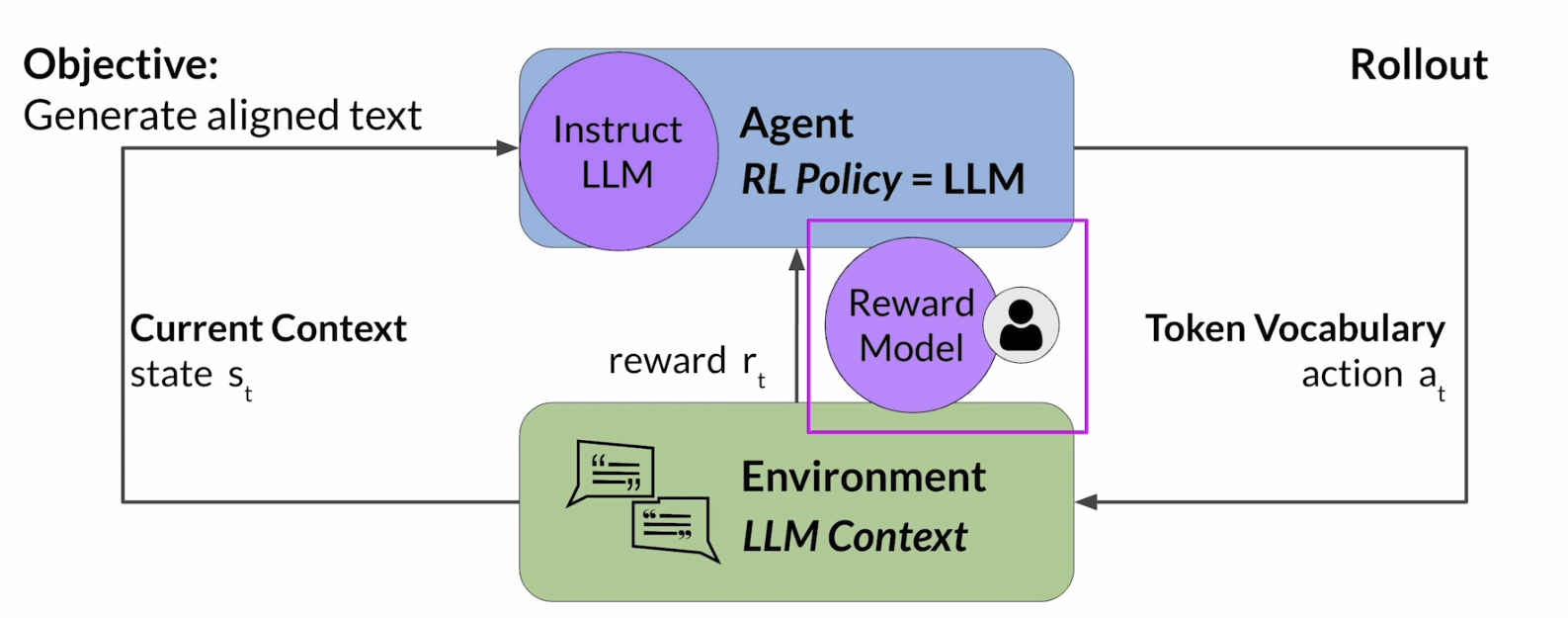
不过这里最大的问题是:reward 到底从哪来?
如果每次都让真人去看模型输出,再打一分,当然最直接,但这件事太慢了,不可能无限扩展。课程里说真人反馈虽然好,但成本高,所以实际做法通常不是让人一直在线打分,而是先收集一部分 human feedback,再训练出一个额外的 reward model。这个 reward model 学到的是“人更喜欢什么样的回答”,之后它就可以代替人,去给 LLM 的输出打分,输出一个 reward signal。
所以从流程上看,RLHF 其实可以粗暴地理解成三层东西叠在一起:
- 一个已经能正常回答问题的 instruct LLM
- 一个从人类偏好中学出来的 reward model
- 一个用 reward 去继续更新 LLM 的 reinforcement learning 过程
也就是说,人类不会直接参与每一步训练,而是先把偏好“蒸馏”进 reward model,再由 reward model 去持续评价 LLM 的输出。这也是为什么课程最后会说:reward model 是 RLHF 里的核心部件,因为它编码了人类偏好,决定了模型后面到底会往什么方向学。
3. RLHF: Obtaining feedback from humans
RLHF 的第一步不是马上做强化学习,而是先准备一批 human feedback 数据。课程这里提到的做法是,先选一个已经有一定能力的模型,通常比较适合从一个 instruct model 开始,因为它至少已经能比较像样地完成任务。然后再配合一个 prompt dataset,让模型针对每个 prompt 生成多个不同的 completions。这样做的目的,不是马上选出“唯一正确答案”,而是先造出一组可供比较的候选回答,后面再交给人来判断哪个更符合我们的 alignment 目标。
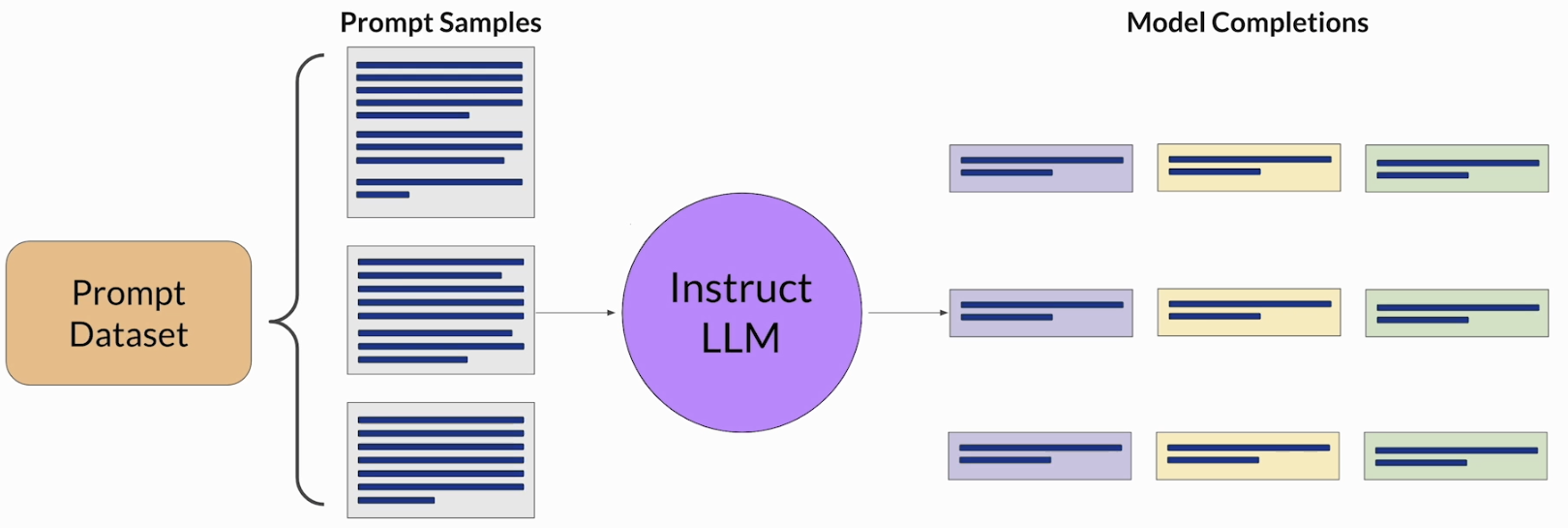
接下来才进入真正的 human feedback。首先要先定义清楚你到底要让人评价什么,也就是 alignment criterion。这个标准可以是 helpfulness、harmlessness、toxicity,也可以是别的更具体的目标。也就是说,标注员不是在凭感觉随便选,而是在围绕一个明确标准去排序模型回答。课程里的例子是:prompt 是 “My house is too hot.”,模型生成了三个不同 completions,然后让标注员按 helpfulness 从高到低排序。
在这个例子里,一个比较合理的结果是,那个真正给出可执行建议、比如提到 air conditioning 的回答(黄色的),会被排在第一。而那种没有帮助甚至有点胡说八道的回答,会排在后面。这里很重要的一点是,human feedback 并不是让人写新答案,而是让人比较模型已经生成出来的答案。这样做更容易标准化,也更方便后面转成 reward model 的训练数据。
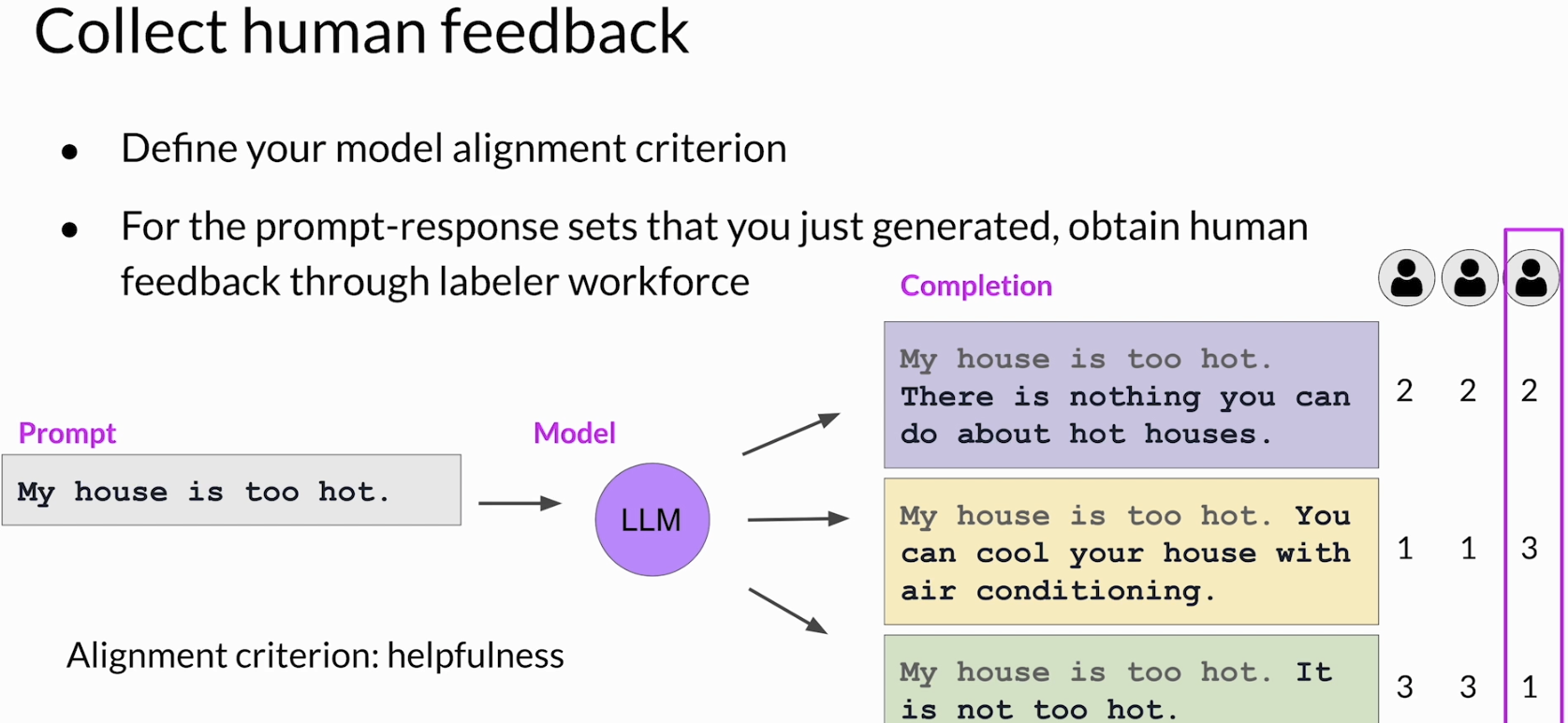
如果标注说明写得清不清楚,会直接影响 human feedback 的质量。因为标注员如果没理解任务,或者各自按不同标准排序,那最后得到的数据就会非常混乱。所以实际做法里,通常会给标注员一整套比较详细的 instructions,告诉他们该根据什么来判断、遇到 tie 怎么办、遇到 nonsense 或 irrelevant answer 怎么处理,甚至可以让他们上网 fact-check。这个部分其实很关键,因为 reward model 后面学到的“人类偏好”,本质上就是从这些标注里蒸馏出来的;如果标注本身不稳定,后面整个 RLHF 链条都会有点歪。
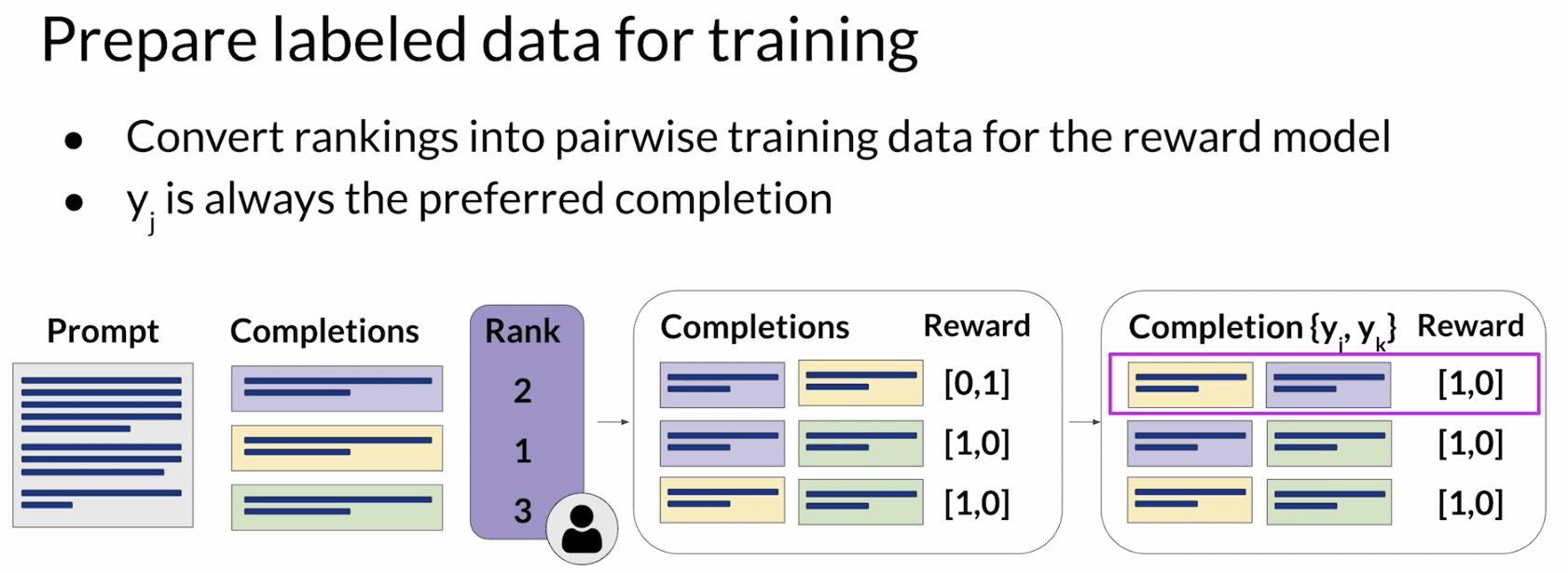
当这些排序数据收集完以后,还不能直接拿去训练 reward model。因为 reward model 更常见的训练形式不是直接学一个“1、2、3 名次”,而是学 pairwise comparison(成对比较)。也就是说,要把一个 prompt 下多个 completions 的排序结果,转换成若干个0或1的二元比较样本(两个样本中更好的为1)。
比如例子为三个 completions,那么从排序结果里可以拆出三组 pair:
- purple vs yellow
- purple vs green
- yellow vs green
对于每一组 pair,都给 preferred completion 标一个 1,另一个标 0。同时还要把顺序排好,让更优的那个 completion 放在前面,因为 reward model 训练时默认前面的那个是 preferred response
4. RLHF: Reward model
前面有说让人在线来对模型的输出进行打分,但是这样效率和成本上都表现极差。因此就需要reward model。它的作用可以简单理解成:先学会模仿人类偏好,后面再代替人去判断模型回答好不好。
reward model 本身通常也是一个语言模型,只不过它现在不负责生成回答,而是负责“评分”。训练它的时候,用的正是前一节整理好的 pairwise comparison data。对于同一个 prompt x,我们已经知道哪个 completion 是人更喜欢的,哪个是相对没那么好的。reward model 要学的,就是给 preferred completion 更高的 reward,给另一个 completion 更低的 reward。课程里把人类更喜欢的那个记作 y_j,另一个记作 y_k,并且默认 $y_j$ 总是排在前面。
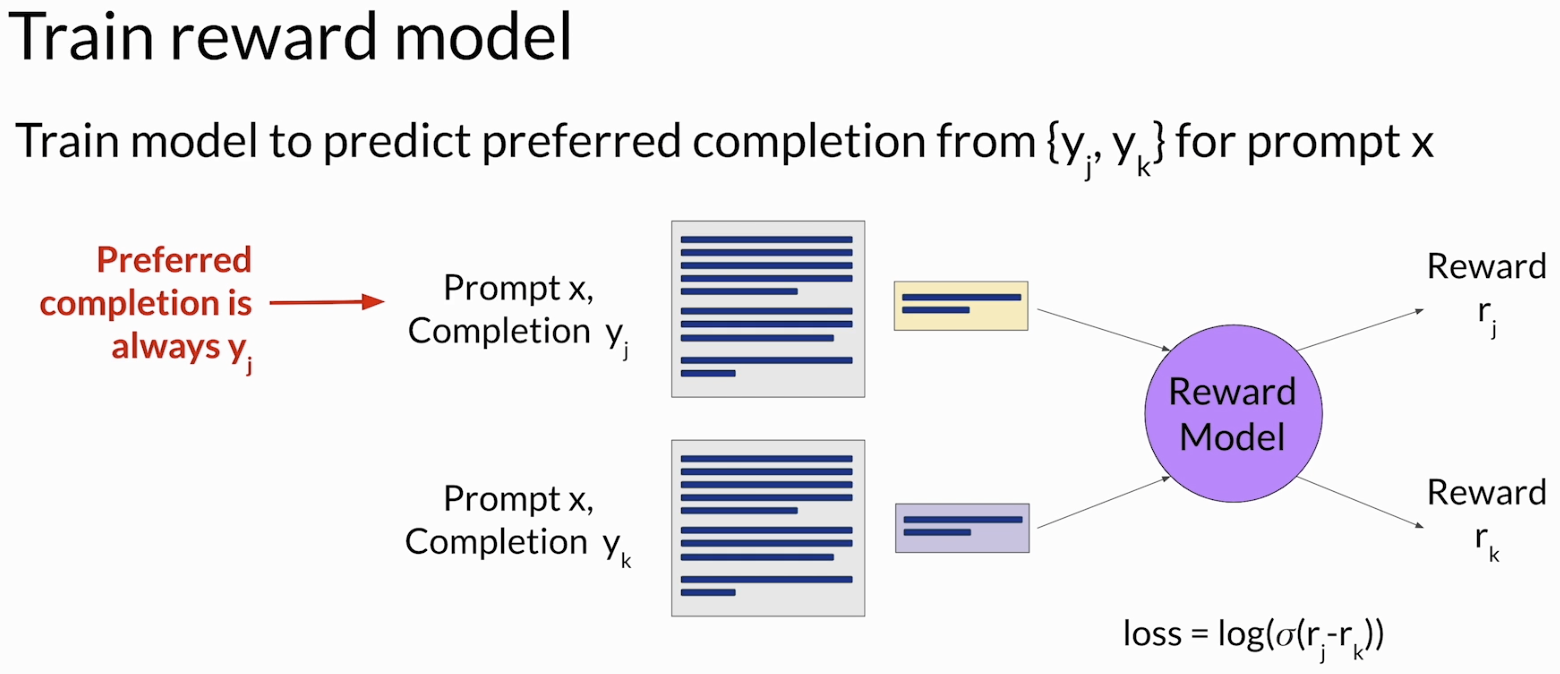
所以 reward model 不是在学“什么是标准答案”,它学的是一种 preference signal(偏好信号)。也就是说,它不需要知道一个 completion 绝对对不对,而是要学会判断在这两个回答里,哪个更符合人类偏好。这一点很重要,因为 RLHF 关注的本来就不是单纯的事实匹配,而是 helpfulness、harmlessness、honesty 这些更接近“人会怎么选”的东西。
训练完成以后,reward model 就可以在 RLHF 过程中顶替人类标注员,自动给 LLM 的输出打分。课程里这里用了一个比较直观的例子:如果你的目标是让模型变得更不 toxic,那么 reward model 就可以被训练成一个类似二分类器的东西,去判断一个 completion 更接近 not hate 还是 hate。但这里真正用来做 reward 的,不是最后硬分类出来的标签,而是模型输出的 logits。
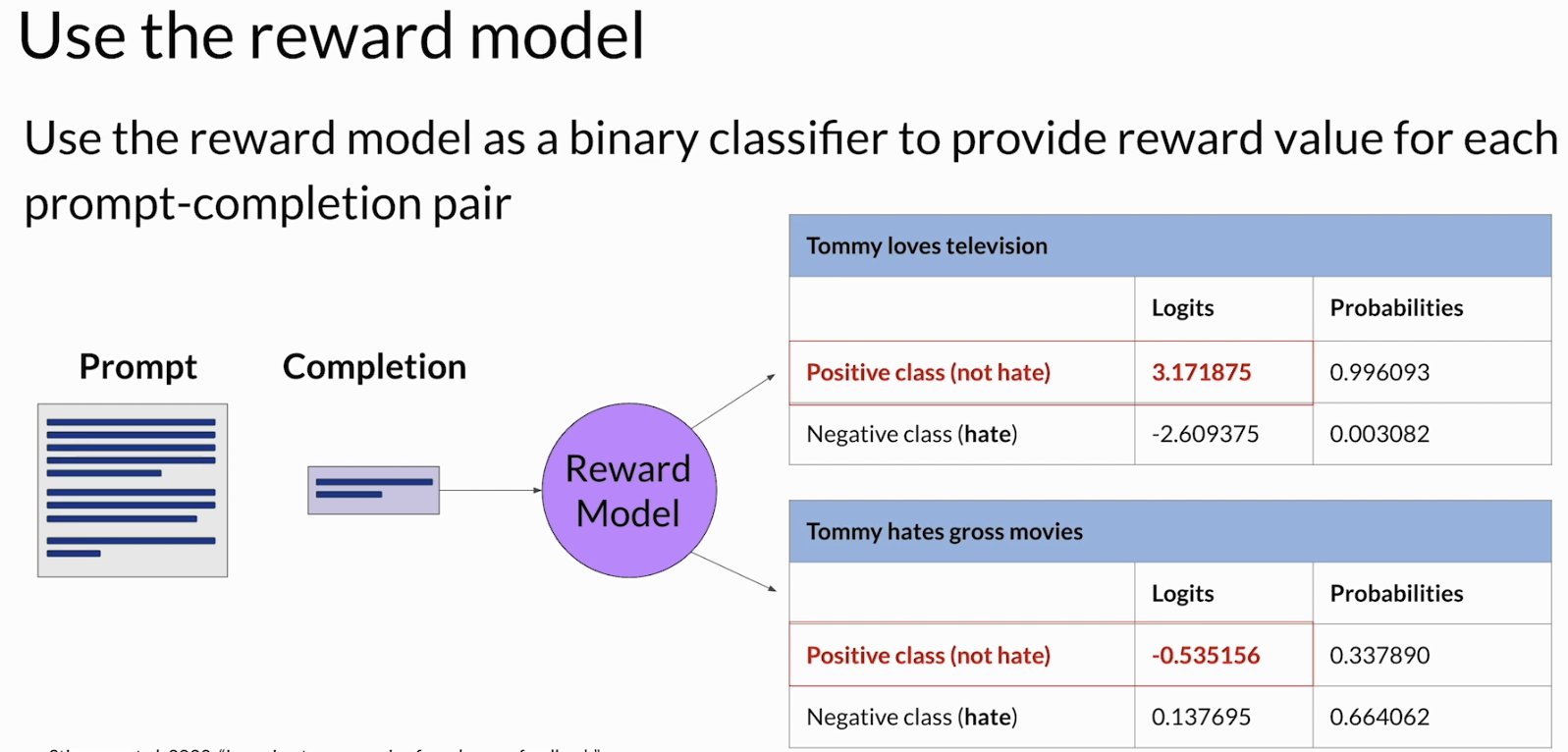
5. RLHF: Fine-tuning with reinforcement learning
前面有说了RLHF所需的两个重要的部分,一个能正常完成任务的 instruction-fine-tuned LLM,以及一个从人类偏好数据中训练出来的 reward model。怎么用reward model所提供的reward signal来继续更新LLM呢。
具体流程是一个迭代闭环。先从 prompt dataset 中取出一个 prompt,输入当前的 LLM,得到一个 completion。然后把这个 prompt-completion pair 送入 reward model,由 reward model 给出一个 reward value。这个分数越高,说明当前回答越符合之前定义的 alignment 目标,比如更 helpful、更 safe,或者更符合人工偏好。
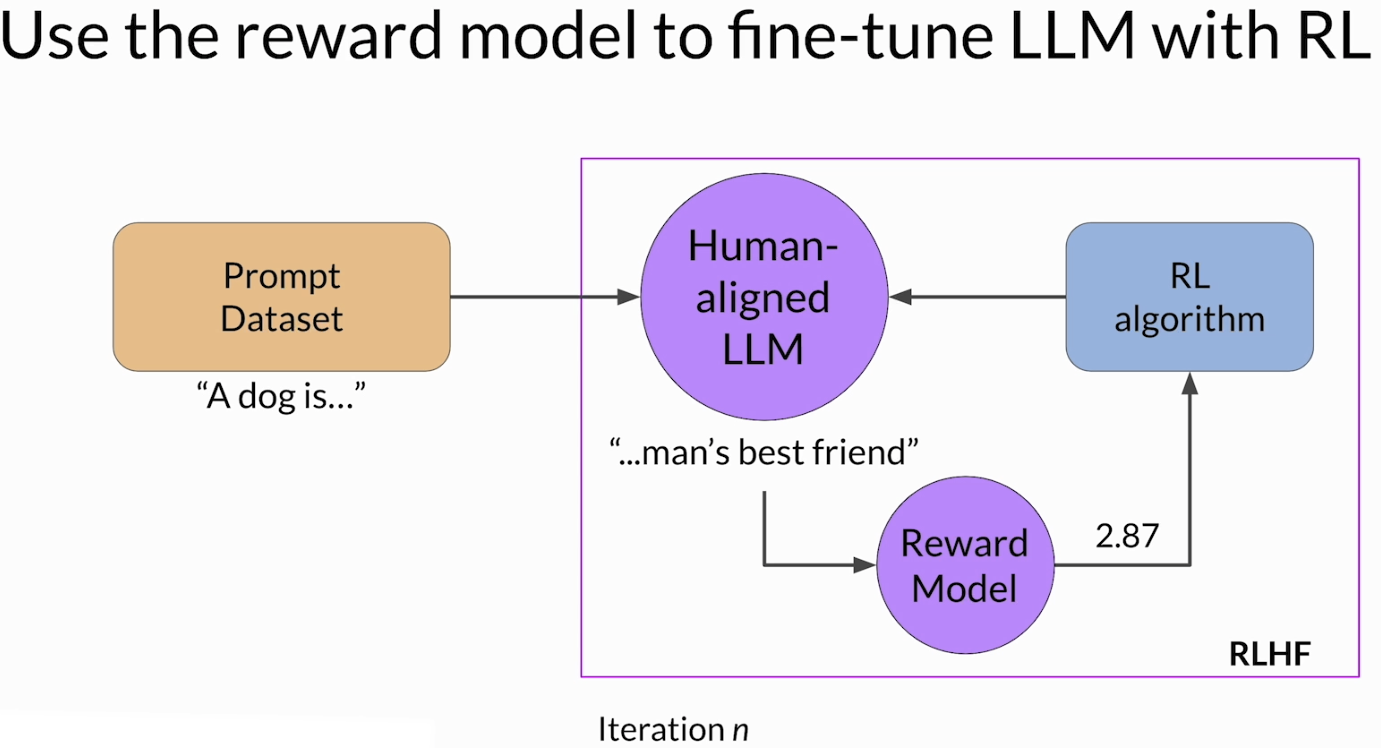
reward model 本身不负责更新 LLM,它只负责打分。真正根据 reward 去修改模型参数的是后面的 reinforcement learning algorithm。也就是说,在 RLHF 里,reward model 扮演的是评价器,RL 算法扮演的是优化器:前者告诉系统“这次回答值几分”,后者根据这个分数去调整 LLM,让它以后更倾向于生成高分回答。
这一轮更新完成后,可以把模型看成一个新的中间版本。然后它继续接收新的 prompt,生成新的 completion,再被 reward model 评分,再继续更新。整个过程会重复很多轮,直到模型在某个评估指标上达到目标,或者训练步数达到预先设定的上限。
从效果上看,如果训练正常进行,随着迭代继续,模型生成内容对应的 reward 应该逐渐上升。这意味着模型正在学会什么样的回答更符合人类偏好,而不是只按原来的语言分布去续写。到了这个阶段,模型就不只是一个 instruct model,而是一个经过进一步对齐的 human-aligned LLM。
课程里提到,这一步常用的优化算法是 PPO(Proximal Policy Optimization)。PPO 负责根据 reward signal 控制参数更新,使模型在提高 reward 的同时,不至于每一步都改得过猛。这里不需要把 PPO 的推导细节全部展开,知道它在 RLHF 里的位置就够了,它是把 reward model 输出的分数真正转化成参数更新的那一层。
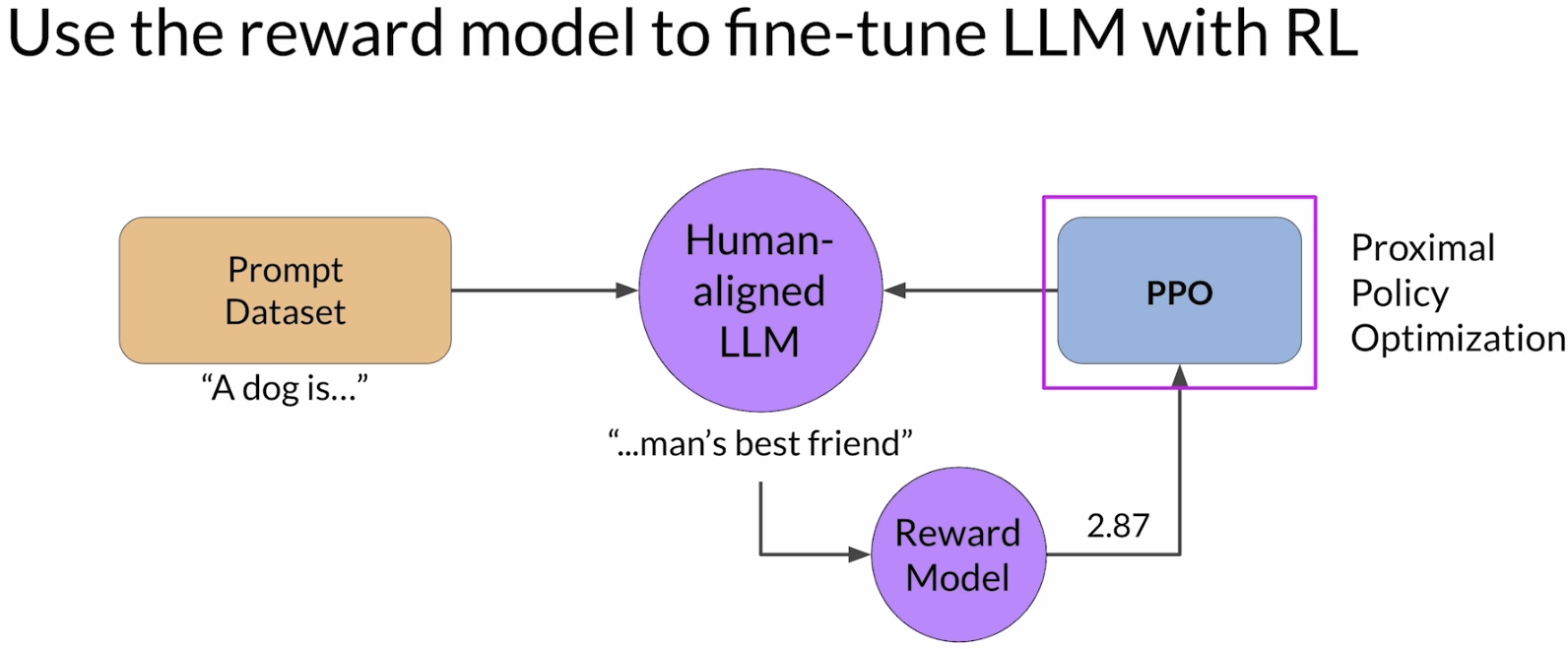
6. Optional: Proximal policy optimization (PPO)
7. RLHF: Reward hacking
8. KL divergence
9. Scaling human feedback
## 3. Deployment
### 3.1 Model optimizations for deployment
## 4. LLM-powered Applications
### 4.1 Generative AI Project Lifecycle Cheat Sheet
### 4.2 Using the LLM in applications
### 4.3 Interacting with external applications
## 5. Reasoning and Action
### 5.1 Helping LLMs reason and plan with chain-of-thought
### 5.2 Program-aided language models (PAL)
### 5.3 ReAct: Combining reasoning and action
### 5.4 ReAct: Reasoning and action
## 6. LLM Application Architectures
### 6.1 LLM application architectures
### 6.2 Optional: AWS SageMaker JumpStart
## 7. Responsible AI